任务一:
实现MIT JOS LAB2 Exercise 1 要求的相关代码。Exercise 1 主要是关于物理内存分配模块的实现,要求make grade通过并回答以下问题:
mem_init函数中kern_pgdir的虚拟地址和物理地址分别是多少?为什么我们在内存的页式管理机制实现前就可以使用虚拟地址映射?请找到对应的代码实现并详细写明原理。- 在
page_init函数中,EXTPHYSMEM之后的已经被使用的内存由哪些部分组成?请打印出对应部分起始的物理地址。
Exercise 1
In the file
kern/pmap.c, you must implement code for the following functions (probably in the order given).
boot_alloc()mem_init()(only up to the call tocheck_page_free_list(1))page_init()page_alloc()page_free()
check_page_free_list()andcheck_page_alloc()test your physical page allocator.
操作系统必须追踪物理RAM的哪些部分是空闲的,哪些被占用了。 JOS以页为最小粒度管理PC的物理内存,使用MMU映射,保护每个分配的内存。
所以需要实现一个物理内存分配器(physical page allocator),将根据struct PageInfo链表进行空闲页面的追踪,链表中每一个结点对应一个物理页。
//inc/memlayout.h
// Page descriptor structures, mapped at UPAGES.
// Read/write to the kernel, read-only to user programs.
// Each struct PageInfo stores metadata for one physical page.
// Is it NOT the physical page itself, but there is a one-to-one correspondence between physical pages and struct PageInfo's.
// You can map a struct PageInfo * to the corresponding physical address with page2pa() in kern/pmap.h.
struct PageInfo {
// Next page on the free list.
// pp_link指向下一个空闲页
struct PageInfo *pp_link;
// pp_ref is the count of pointers (usually in page table entries)
// to this page, for pages allocated using page_alloc.
// Pages allocated at boot time using pmap.c's
// boot_alloc do not have valid reference count fields.
// pp_ref表示页面被引用数,如果为0,表示是空闲页
uint16_t pp_ref;
};
Exercise 1要求实现kern/pmap.c 中的以下函数:
boot_alloc()mem_init()page_init()page_alloc()page_free()
boot_alloc()
boot_alloc函数在mem_init()函数中被调用,目的是创建一个页目录。
// create initial page directory.
kern_pgdir = (pde_t *) boot_alloc(PGSIZE);
memset(kern_pgdir, 0, PGSIZE);
根据注释可以知道:boot_alloc函数只在建立虚拟内存系统时使用,真正分配器是page_alloc。如果传入的参数n>0,将分配一个n字节的连续物理内存,返回虚拟地址;n=0,不分配,并返回下一个空闲页。
// This simple physical memory allocator is used only while JOS is setting up its virtual memory system.
// page_alloc() is the real allocator.
// If n>0, allocates enough pages of contiguous physical memory to hold 'n' bytes.
// Doesn't initialize the memory. Returns a kernel virtual address.
//
// If n==0, returns the address of the next free page without allocating anything.
//
// If we're out of memory, boot_alloc should panic.
// This function may ONLY be used during initialization, before the page_free_list list has been set up.
这段代码的核心是要维护好静态变量nextfree。nextfree指向下一个空闲字节,在boot_alloc()已有的代码中把nextfree指向了.bss后面(因为end表示.bss段结束处,.bss段是内核的最后一段,end相当于指向的是第一个未使用的虚拟内存地址)。
所以要做的事是在这个基础上继续分配大小为n的空间,按照要求如果n==0,直接返回nextfree的地址;如果n>0,则移动nextfree,分配大小为n的空间,但是如果分配超出空间out of memory,需要panic。
分配的上限是KERNBASE+(npages * PGSIZE),如果超过了就报错panic。
static void *
boot_alloc(uint32_t n)
{
static char *nextfree; // virtual address of next byte of free memory
char *result;
if (!nextfree)
{
extern char end[];
nextfree = ROUNDUP((char *)end, PGSIZE);
}
// Allocate a chunk large enough to hold 'n' bytes, then update nextfree.
// Make sure nextfree is kept aligned to a multiple of PGSIZE.
// LAB 2: Your code here.
if (n == 0)
return nextfree;
//n>0
result = nextfree;
nextfree = ROUNDUP((char *)(nextfree + n), PGSIZE);
if ((uint32_t)nextfree - KERNBASE > (npages * PGSIZE))
panic("boot_alloc:out of memory!\n");
return result;
}
mem_init()
mem_init() 的主要作用是设置一个二级页表。根据注释,填充部分的作用是:对于存储PageInfo的数组pages进行空间分配,并且初始化为0。PageInfo的结构在之前有提到。
//kern/pmap.h
extern struct PageInfo *pages;
extern size_t npages;
通过boot_alloc函数实现分配相应空间,再用memset来初始化所有的PageInfo,全部都置为0。
//////////////////////////////////////////////////////////////////////
// Allocate an array of npages 'struct PageInfo's and store it in 'pages'.
// The kernel uses this array to keep track of physical pages: for
// each physical page, there is a corresponding struct PageInfo in this
// array. 'npages' is the number of physical pages in memory. Use memset
// to initialize all fields of each struct PageInfo to 0.
// Your code goes here:
pages = (struct PageInfo *)boot_alloc(npages * sizeof(struct PageInfo));
memset(pages, 0, npages * sizeof(struct PageInfo));
page_init()
page_init()的主要作用是:始化页的数据结构以及初始化能够分配的空闲物理空间页的链表(page_free_list),并且一旦执行完page_init(),就再也不会执行boot_alloc。
// The example code here marks all physical pages as free.
// However this is not truly the case. What memory is free?
// 1) Mark physical page 0 as in use.
// This way we preserve the real-mode IDT and BIOS structures
// in case we ever need them. (Currently we don't, but...)
// 2) The rest of base memory, [PGSIZE, npages_basemem * PGSIZE) is free.
// 3) Then comes the IO hole [IOPHYSMEM, EXTPHYSMEM), which must never be allocated.
//
// 4) Then extended memory [EXTPHYSMEM, ...).
// Some of it is in use, some is free. Where is the kernel in physical memory?
// Which pages are already in use for page tables and other data structures?
//
//
// Change the code to reflect this.
// NB: DO NOT actually touch the physical memory corresponding to
// free pages!
// 这里的代码把所有的物理页都标记为free
size_t i;
for (i = 0; i < npages; i++)
{
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
page_init()中给出了很详细的注释:
- 需要把物理页
0标志为正在使用 [PGSIZE, npages_basemem * PGSIZE)这部分base memory是可用的I/O hole不可以被分配,所以不可以被标记为freeI/O hole之后的extended memory中有一部分被kernel占用,这部分不能被标记为free。可以通过调用boot_alloc(0)找出未被分配的物理地址,即内核分配的最后的物理地址。注意:boot_alloc返回的是虚拟地址,可以通过宏PADDR转为物理地址
对所有不可被分配的,pp_ref设为1;空闲可用的,pp_ref标记为0。
void page_init(void)
{
size_t i;
// page 0
pages[0].pp_ref = 1;
// [PGSIZE, npages_basemem * PGSIZE)都可用,npages_basemem在i386_detect_memory中获得
for (i = 1; i < npages_basemem; i++)
{
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
// [IOPHYSMEM, EXTPHYSMEM)
for (i = IOPHYSMEM / PGSIZE; i < EXTPHYSMEM / PGSIZE; i++)
pages[i].pp_ref = 1;
// [EXTPHYSMEM, ...)
// 这部分被kernel占用,不可用
size_t first_free_page = PADDR(boot_alloc(0)) / PGSIZE;
for (i = EXTPHYSMEM / PGSIZE; i < first_free_page; i++)
pages[i].pp_ref = 1;
// 其他部分都可用
for (i = first_free_page; i < npages; i++)
{
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
}
page_alloc()
通过注释可以看到page_alloc()的作用是:分配一个物理页面,即从page_free_list中分配一个空闲页,函数的返回值就是这个物理页所对应的PageInfo结构体。在还有空闲物理页的情况下,先对空闲链表进行修改指针,然后如果(alloc_flags & ALLOC_ZERO),则用\0填充。
// Allocates a physical page.
// If (alloc_flags & ALLOC_ZERO), fills the entire returned physical page with '\0' bytes.
// Does NOT increment the reference count of the page - the caller must do these if necessary (either explicitly or via page_insert).
//
// Be sure to set the pp_link field of the allocated page to NULL so page_free can check for double-free bugs.
//
// Returns NULL if out of free memory.
//
// Hint: use page2kva and memset
提示中提到了page2kva函数,该函数的作用是:将page_alloc取出分配的物理页转化为虚拟地址,即逻辑地址。
static inline void* page2kva(struct PageInfo *pp)
{
return KADDR(page2pa(pp));
}
代码如下:
struct PageInfo * page_alloc(int alloc_flags)
{
// Fill this function in
// 如果有空闲页
if (page_free_list)
{
struct PageInfo *allocated = page_free_list;
// 修改指针
page_free_list = allocated->pp_link;
allocated->pp_link = NULL;
if (alloc_flags & ALLOC_ZERO)
memset(page2kva(allocated), '\0', PGSIZE);
return allocated;
}
else
return NULL;
}
page_free()
page_free()的作用是释放一个页面,该页面加入page_free_list。根据提示:如果要释放的页面pp->pp_ref非零或者pp->pp_link不是NULL则报错。
//
// Return a page to the free list.
// (This function should only be called when pp->pp_ref reaches 0.)
//
void page_free(struct PageInfo *pp)
{
// Fill this function in
// Hint: You may want to panic if pp->pp_ref is nonzero or
// pp->pp_link is not NULL.
if (pp->pp_ref)
panic("page_free:page %p's pp->pp_ref is nonzero", pp);
else if (pp->pp_link)
panic("page_free:page %p's pp->pp_link is not NULL", pp);
pp->pp_link = page_free_list;
page_free_list = pp;
}
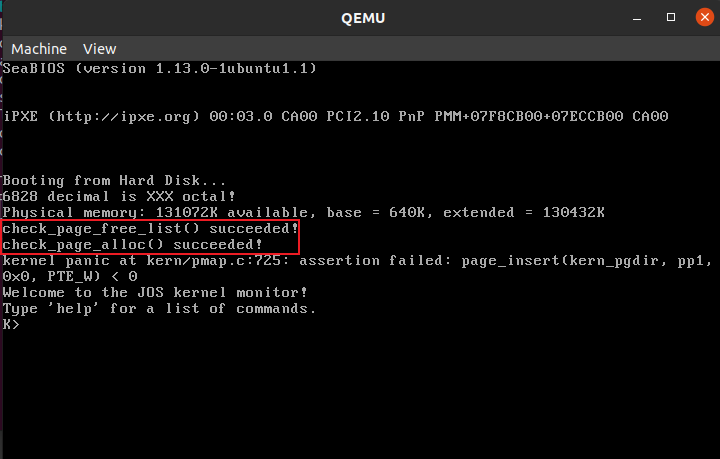
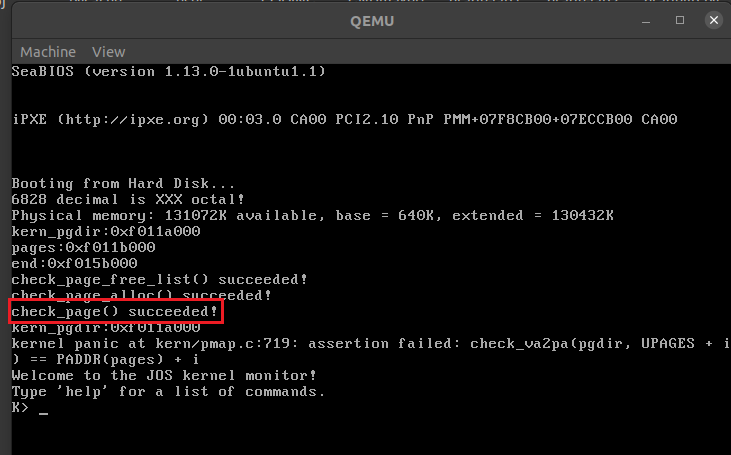
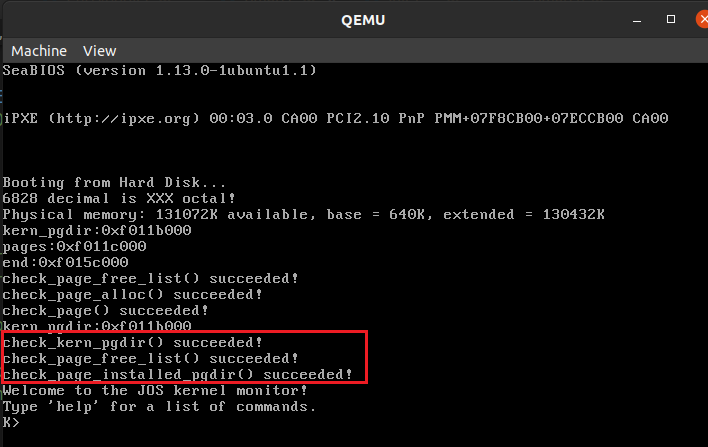
运行截图:
make qemu,显示check_page_free_list() succeeded!和check_page_alloc() succeeded!,说明Exercise 1的5个函数正确运行。
回答问题1
mem_init函数中kern_pgdir的虚拟地址和物理地址分别是多少?为什么我们在内存的页式管理机制实现前就可以使用虚拟地址映射?请找到对应的代码实现并详细写明原理。
A:
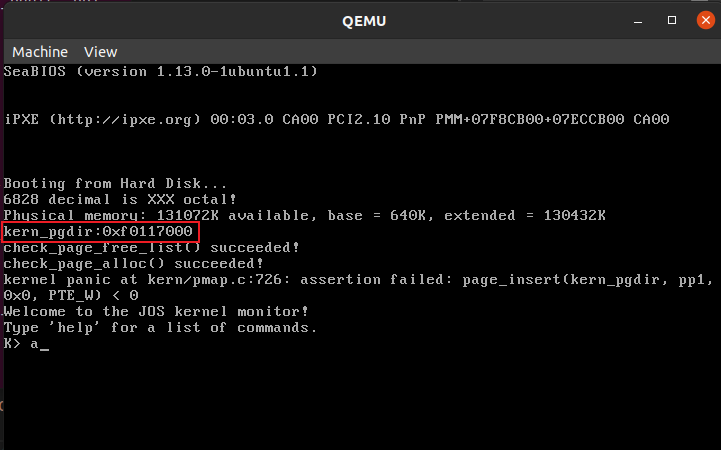
mem_init函数中kern_pgdir的虚拟地址和物理地址:
kern_pgdir = (pde_t *)boot_alloc(PGSIZE);
memset(kern_pgdir, 0, PGSIZE);
cprintf("kern_pgdir:0x%08x\n", kern_pgdir);
打印得到kern_pgdir的虚拟地址:0xf0117000
物理地址 = 虚拟地址 - kernbase,从memlayout.h的内存分配图中可以看出kernbase = 0xf0000000。所以kern_pgdir的物理地址=0xf0117000 - 0xf0000000 = 0x00117000(也可以用宏PADDR转换为物理地址后再打印出来)
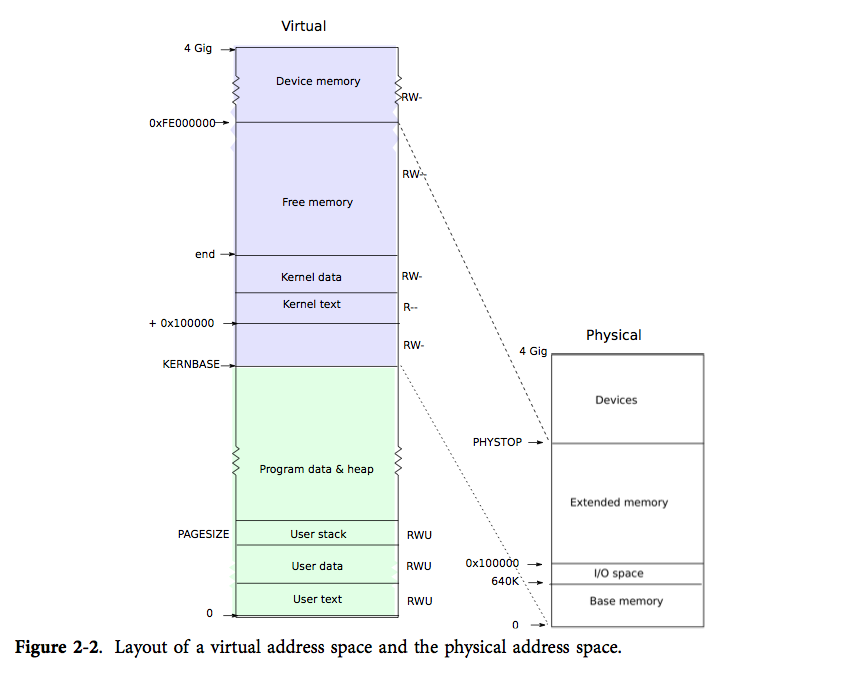
* |~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~| RW/--
* | | RW/--
* | Remapped Physical Memory | RW/--
* | | RW/--
* KERNBASE, ----> +------------------------------+ 0xf0000000 --+
* KSTACKTOP | CPU0's Kernel Stack | RW/-- KSTKSIZE |
* | - - - - - - - - - - - - - - -| |
为什么在内存的页式管理机制实现前就可以使用虚拟地址映射?
在Lab 1的kern\entrygdir.c中,实现了映射4M的物理空间(即映射了一页),把虚拟地址空间的地址范围:0xf0000000~0xf0400000和0x00000000~0x00400000,都映射到物理地址范围:0x00000000~0x00400000。
在kern/entrypgdir.c中有这样一段注释:
// The entry.S page directory maps the first 4MB of physical memory
// starting at virtual address KERNBASE (that is, it maps virtual
// addresses [KERNBASE, KERNBASE+4MB) to physical addresses [0, 4MB)).
// We choose 4MB because that's how much we can map with one page
// table and it's enough to get us through early boot. We also map
// virtual addresses [0, 4MB) to physical addresses [0, 4MB); this
// region is critical for a few instructions in entry.S and then we
// never use it again.
说明在内存的页式管理机制实现前,在kern/entry.S中已经完成了虚拟地址[KERNBASE, KERNBASE+4MB)到物理地址[0, 4MB)的映射,而这段空间足够用来实现early boot。
具体的映射代码如下:
// kern/entrypgdir.c
pte_t entry_pgtable[NPTENTRIES];
__attribute__((__aligned__(PGSIZE)))
pde_t entry_pgdir[NPDENTRIES] = {
// Map VA's [0, 4MB) to PA's [0, 4MB)
[0]
= ((uintptr_t)entry_pgtable - KERNBASE) + PTE_P,
// Map VA's [KERNBASE, KERNBASE+4MB) to PA's [0, 4MB)
[KERNBASE>>PDXSHIFT]
= ((uintptr_t)entry_pgtable - KERNBASE) + PTE_P + PTE_W
};
再看kern/entry.S中的汇编,直接使用了映射好的entry_pgdir。
.globl entry
entry:
movw $0x1234,0x472 # warm boot
# We haven't set up virtual memory yet, so we're running from
# the physical address the boot loader loaded the kernel at: 1MB
# (plus a few bytes). However, the C code is linked to run at
# KERNBASE+1MB. Hence, we set up a trivial page directory that
# translates virtual addresses [KERNBASE, KERNBASE+4MB) to
# physical addresses [0, 4MB). This 4MB region will be
# sufficient until we set up our real page table in mem_init
# in lab 2.
# Load the physical address of entry_pgdir into cr3. entry_pgdir
# is defined in entrypgdir.c.
# 将 entry_pgdir 的物理地址保存到cr3寄存器,entry_pgdir中定义了VA到PA的映射
# cr3寄存器的作用是让处理器可以翻译线性地址为物理地址
movl $(RELOC(entry_pgdir)), %eax
movl %eax, %cr3
# Turn on paging.
# 这部分指令启动了分页机制
movl %cr0, %eax
orl $(CR0_PE|CR0_PG|CR0_WP), %eax
movl %eax, %cr0
# Now paging is enabled, but we're still running at a low EIP
# Jump up above KERNBASE before entering C code.
# 进入高地址
mov $relocated, %eax
jmp *%eax
回答问题2
在
page_init函数中,EXTPHYSMEM之后的已经被使用的内存由哪些部分组成?请打印出对应部分起始的物理地址。
A:EXTPHYSMEM的地址为0x100000

在lab1中有介绍PC物理地址的分布,如下图:
+------------------+ <- 0xFFFFFFFF (4GB)
| 32-bit |
| memory mapped |
| devices |
| |
/\/\/\/\/\/\/\/\/\/\
/\/\/\/\/\/\/\/\/\/\
| |
| Unused |
| |
+------------------+ <- depends on amount of RAM
| |
| |
| Extended Memory |
| |
| |
+------------------+ <- 0x00100000 (1MB)
| BIOS ROM |
+------------------+ <- 0x000F0000 (960KB)
| 16-bit devices, |
| expansion ROMs |
+------------------+ <- 0x000C0000 (768KB)
| VGA Display |
+------------------+ <- 0x000A0000 (640KB)
| |
| Low Memory |
| |
+------------------+ <- 0x00000000
在lab1中介绍了:操作系统内核程序在虚拟地址空间通常会被链接到一个非常高的虚拟地址空间处,比如0xf0100000,目的就是能够让处理器的虚拟地址空间的低地址部分能够被用户利用来进行编程。但是许多的机器并没有能够支持0xf0100000这种地址那么大的物理内存,所以不能把内核的0xf0100000虚拟地址简单地映射到物理地址0xf0100000,而是放在一个低的物理地址空间处如0x00100000(JOS中就是这样的)。
所以EXTPHYSMEM之后的第一部分是Kernel code,之后的部分是由boot_alloc分配的,其中参数n大于0的情况下只被调用了两次,分别是在mem_init()中创建页目录和对于存储PageInfo的数组pages进行空间分配。分别打印位置。
void mem_init(void)
{
//////////////////////////////////////////////////////////////////////
// create initial page directory.
kern_pgdir = (pde_t *)boot_alloc(PGSIZE);
memset(kern_pgdir, 0, PGSIZE);
cprintf("kern_pgdir VA:0x%08x\n", kern_pgdir);
cprintf("kern_pgdir PA:0x%08x\n", PADDR(kern_pgdir));
//////////////////////////////////////////////////////////////////////
// Allocate an array of npages 'struct PageInfo's and store it in 'pages'.
// The kernel uses this array to keep track of physical pages: for
// each physical page, there is a corresponding struct PageInfo in this
// array. 'npages' is the number of physical pages in memory. Use memset
// to initialize all fields of each struct PageInfo to 0.
// Your code goes here:
pages = (struct PageInfo *)boot_alloc(npages * sizeof(struct PageInfo));
memset(pages, 0, npages * sizeof(struct PageInfo));
cprintf("pages VA:0x%08x\n", pages);
cprintf("pages PA:0x%08x\n", PADDR(pages));
void *end = boot_alloc(0);
cprintf("end VA:0x%08x\n", end);
cprintf("end PA:0x%08x\n", PADDR(end));
}
结果如图所示:
(这里因为把后面的Exercise 4&5做完了再来回答这个问题,所以kern_pgdir的地址和上一个回答中有区别)
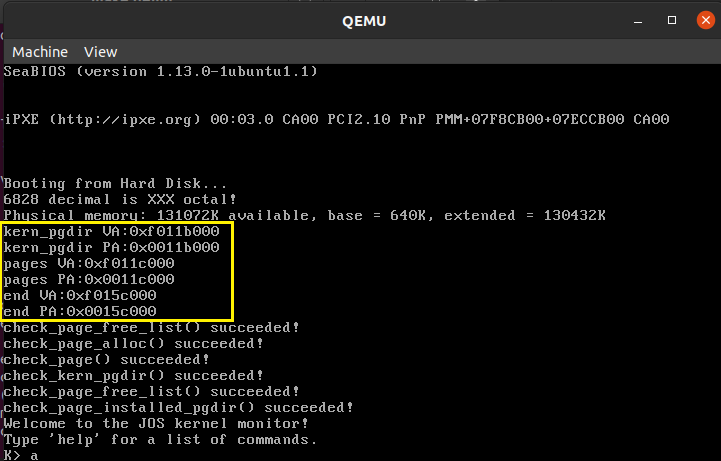
EXTPHYSMEM之后的已经被使用的内存由三部分组成,物理地址分别是:
-
kernel code:
0x00100000-0x0011b000 -
kern_pgdir:0x0011b000-0x0011c000 -
pages:0x0011c000-0x0015c000
任务二:
阅读MIT JOS LAB2 Part 2 部分关于虚拟内存的介绍以及
kern/pmap.h和inc/mmu.h的源码,实现 Exercise 4 要求的相关代码,要求make grade通过并回答以下问题:
- 请你写出你实现的
pgdir_walk中的变量有哪些是虚拟地址,哪些是物理地址,以及为什么是这样。page_insert注释中提到了一个和reinsert相关的corner case,请问是否有办法在不特殊处理的情况下巧妙规避掉这个corner case。- 阅读参考资料3,阐述使用
uvpt[PGNUM(va)]可以直接得到va对应的pte的原理。
Exercise 4
要求编写管理页表的例程:插入以及删除线性地址到物理地址的映射,同时还需要创建页表。实现
kern/pmap.c中的:
pgdir_walk()boot_map_region()page_lookup()page_remove()page_insert()
check_page(), called frommem_init(), tests your page table management routines. You should make sure it reports success before proceeding.
首先在mmu.h中可以找到JOS虚拟地址的结构。(因为只有一个段,所以虚拟地址数值上等于线性地址)
// A linear address 'la' has a three-part structure as follows:
//
// +--------10------+-------10-------+---------12----------+
// | Page Directory | Page Table | Offset within Page |
// | Index | Index | |
// +----------------+----------------+---------------------+
// \--- PDX(la) --/ \--- PTX(la) --/ \---- PGOFF(la) ----/
// \---------- PGNUM(la) ----------/
虚拟地址的翻译过程主要就是根据下面这张图。其中page_dir和page_table代表了二级页表。
整体过程是:先通过CR3寄存器找到PAGE_DIR的位置,然后通过虚拟地址的前10位Page Directory Index在PAGE_DIR中获取到下一级页表PAGE_TABLE的地址;然后通过虚拟地址的中间10位Page Table Index找到对应的PAGE_FRAME的地址;再将从中获取到的物理页号结合最后12位Offset within Page获得最终的物理地址了。
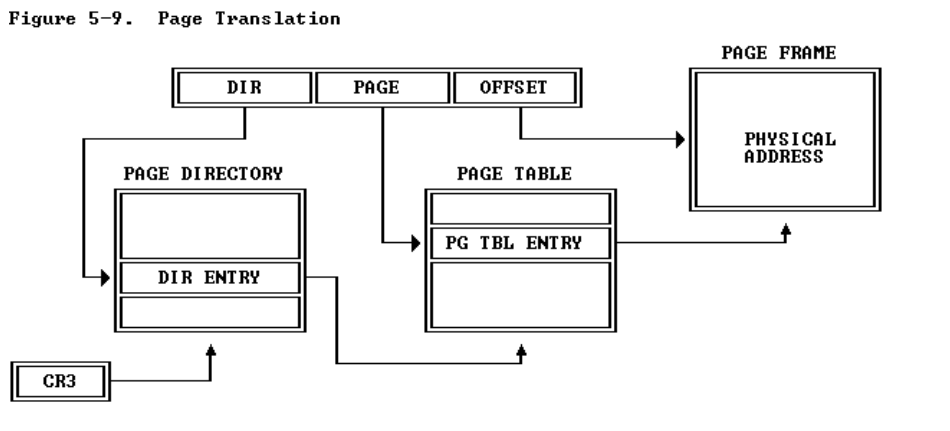
pgdir_walk()
该函数前面有很长一段注释介绍函数的具体作用,简单来说这个函数实现了虚拟地址到实际物理地址的翻译过程,以页目录pgdir和线性地址va作为参数,返回一个指向PTE(线性地址对应的页面所在页表项)的指针。
// Given 'pgdir', a pointer to a page directory, pgdir_walk returns a pointer to the page table entry (PTE) for linear address 'va'.
// pgdir_walk()以页目录pgdir和线性地址va作为参数,返回一个指向PTE(线性地址对应的页面所在页表项)的指针
// This requires walking the two-level page table structure.
// 是一个二级页表,和上图一样
//
// The relevant page table page might not exist yet.
// If this is true, and create == false, then pgdir_walk returns NULL.
// 相关页可能不存在,如果不存在且create == false,函数返回NULL
// Otherwise, pgdir_walk allocates a new page table page with page_alloc.
// - If the allocation fails, pgdir_walk returns NULL.
// - Otherwise, the new page's reference count is incremented, the page is cleared, and pgdir_walk returns a pointer into the new page table page.
// 否则用page_alloc分配一个页面,分配失败返回NULL;分配成功,新页的引用次数+1,页清空,返回页指针
并且根据提示在mmu.h中找到了一些有用的宏,可以取出对应的索引或者偏移:
// page directory index
#define PDX(la) ((((uintptr_t) (la)) >> PDXSHIFT) & 0x3FF)
// page table index
#define PTX(la) ((((uintptr_t) (la)) >> PTXSHIFT) & 0x3FF)
// Address in page table or page directory entry
#define PTE_ADDR(pte) ((physaddr_t) (pte) & ~0xFFF)
// Page table/directory entry flags.标志位
#define PTE_P 0x001 // Present
#define PTE_W 0x002 // Writeable
#define PTE_U 0x004 // User
#define PTE_PWT 0x008 // Write-Through
#define PTE_PCD 0x010 // Cache-Disable
#define PTE_A 0x020 // Accessed
#define PTE_D 0x040 // Dirty
#define PTE_PS 0x080 // Page Size
#define PTE_G 0x100 // Global
还有一个pmap.h中有用的:
// a physical address and returns the corresponding kernel virtual address.
// It panics if you pass an invalid physical address. */
#define KADDR(pa) _kaddr(__FILE__, __LINE__, pa)
enum {
// For page_alloc, zero the returned physical page.
ALLOC_ZERO = 1<<0,
};
梳理一下思路:
- 利用上述的宏取出索引或偏移
- 首先检查页目录中对应的页表是否存在:
- 如果存在,直接取出然后计算
pte - 如果
page_dir对应的PTE_P(有效位)=0,说明相关的页目录条目不存在,根据create判断是否要进行page_alloc- 如果
create == false,函数返回NULL - 否则,需要
page_alloc来分配一个物理页面用来存储页表,并且增加该物理页面的引用,将其填入对应的页目录的项中,同样计算pte
- 如果
- 如果存在,直接取出然后计算
代码如下:
pte_t * pgdir_walk(pde_t *pgdir, const void *va, int create)
{
// 获取page directory index
uint32_t dir_idx = PDX(va);
// 获取page table index
uint32_t tab_idx = PTX(va);
// 找到该dir_entry
pte_t *dir_entry = &pgdir[dir_idx];
// 判断有效位是否为0
if (!(*dir_entry & PTE_P)) {
// create=false
if (!create)
return NULL;
// page_alloc
struct PageInfo *newPage = page_alloc(ALLOC_ZERO);
// page_alloc failed
if (newPage == NULL)
return NULL;
// 引用+1
newPage->pp_ref++;
// 根据提示1,通过page2pa把PageInfo *转变为物理地址,并且增加Present、Writeable、User的有效位
// 加入pgdir
*dir_entry = (pde_t)page2pa(newPage) | PTE_P | PTE_U | PTE_W;
}
// 通过PTE_ADDR找到page directory entry中的地址
// 再通过KADDR转换为虚拟地址
pte_t *ptab = (pte_t *)KADDR(PTE_ADDR(*dir_entry));
// 返回指向PTE的指针
return &ptab[tab_idx];
}
boot_map_region()
先看注释,boot_map_region()主要作用是:把虚拟地址[va, va+size)映射到物理地址[pa, pa+size],并且把映射关系加入到页表pgdir,映射的地址的大小是页面大小的整数倍,使用权限位为perm|PTE_P。并且由于是在UTOP上方做静态映射,所以不能修改pp_ref字段。
可以通过上面实现的pgdir_walk函数找到给定虚拟地址对应的pte,然后修改pte条目。
// Map [va, va+size) of virtual address space to physical [pa, pa+size)
// in the page table rooted at pgdir. Size is a multiple of PGSIZE, and
// va and pa are both page-aligned.
// Use permission bits perm|PTE_P for the entries.
//
// This function is only intended to set up the ``static'' mappings
// above UTOP. As such, it should *not* change the pp_ref field on the
// mapped pages.
//
// Hint: the TA solution uses pgdir_walk
代码实现如下:
static void boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm)
{
// Fill this function in
// 首先计算页数
// 因为Size is a multiple of PGSIZE并且va and pa are both page-aligned
// 所以可以直接除,不用ROUNDUP
size_t page_num = size / PGSIZE;
for (size_t i = 0; i < page_num; i++)
{
// 通过pgdir_walk把映射加入pgdir
// 由于va类型是uintptr_t,需要强制转换成void *
pte_t *pte = pgdir_walk(pgdir, (void *)(va + i * PGSIZE), 1);
if (pte == NULL) {
panic("boot_map_region: pgdir_walk failed\n");
}
// 修改va对应的PTE的值
*pte = (pa + i * PGSIZE) | perm | PTE_P;
}
}
page_lookup()
注释中可以看到,该函数的功能是:对于给定的虚拟地址va以及相应的页目录地址pgdir,查找对应的映射页的PageInfo结构并返回。
如果page_lookup()的第三个参数pte_store不为0,则把这个物理页存到pte_store中;如果没有映射的物理页,则返回NULL。最后获取pte中PPN对应的物理地址,根据物理地址获取PageInfo将其返回。
// Return the page mapped at virtual address 'va'.
// If pte_store is not zero, then we store in it the address of the pte for this page.
// This is used by page_remove and can be used to verify page permissions for syscall arguments,
// but should not be used by most callers.
//
// Return NULL if there is no page mapped at va.
//
// Hint: the TA solution uses pgdir_walk and pa2page.
根据提示,可以使用pgdir_walk获取pte,如果没有找到,说明va并没有映射到任何物理页面;如果找到说明该虚拟地址被映射到了一个页面,首先判断pte_store是否为空,如果非空,则把物理页保存到pte_store,然后通过pa2page()转换映射页面的物理页面首地址。
struct PageInfo * page_lookup(pde_t *pgdir, void *va, pte_t **pte_store)
{
// Fill this function in
pte_t *pte = pgdir_walk(pgdir, va, 0);
// va没有映射到物理页面
if (pte == NULL)
return NULL;
if (pte_store)
*pte_store = pte;
return pa2page(PTE_ADDR(*pte));
}
其中PTE_ADDR的作用:
// Address in page table or page directory entry
#define PTE_ADDR(pte) ((physaddr_t) (pte) & ~0xFFF)
page_remove()
// Unmaps the physical page at virtual address 'va'.
// If there is no physical page at that address, silently does nothing.
//
// Details:
// - The ref count on the physical page should decrement.
// - The physical page should be freed if the refcount reaches 0.
// - The pg table entry corresponding to 'va' should be set to 0.
// (if such a PTE exists)
// - The TLB must be invalidated if you remove an entry from
// the page table.
//
// Hint: The TA solution is implemented using page_lookup, tlb_invalidate, and page_decref.
先分析注释,page_remove()的作用是解除va与对应物理页的映射关系,如果va没有对应物理页,什么都不用做。
注释中又给出详细信息:
-
物理页中的
ref计数需要减少。如果物理页的ref计数减到0,需要被free。(可以用Hint中提到的page_decref实现)// Decrement the reference count on a page, // freeing it if there are no more refs. void page_decref(struct PageInfo *pp) { if (--pp->pp_ref == 0) page_free(pp); } -
修改页表项中的对应内容,本来和
va相关联,现在应该设为0 -
修改TLB,通过
tlb_invalidate使得对应的TLB无效// Invalidate a TLB entry, but only if the page tables being // edited are the ones currently in use by the processor. void tlb_invalidate(pde_t *pgdir, void *va) { // Flush the entry only if we're modifying the current address space. // For now, there is only one address space, so always invalidate. invlpg(va); }
代码实现如下:
void page_remove(pde_t *pgdir, void *va)
{
// Fill this function in
pte_t *pte;
struct PageInfo *page = page_lookup(pgdir, va, &pte);
// 对应物理页不存在
if (!page)
return;
// 对应物理页存在
// ref--;pte=0;invalid tlb
page_decref(page);
*pte = 0;
tlb_invalidate(pgdir, va);
}
page_insert()
// Map the physical page 'pp' at virtual address 'va'.
// The permissions (the low 12 bits) of the page table entry should be set to 'perm|PTE_P'.
//
// Requirements
// - If there is already a page mapped at 'va', it should be page_remove()d.
// - If necessary, on demand, a page table should be allocated and inserted into 'pgdir'.
// - pp->pp_ref should be incremented if the insertion succeeds.
// - The TLB must be invalidated if a page was formerly present at 'va'.
//
// Corner-case hint: Make sure to consider what happens when the same
// pp is re-inserted at the same virtual address in the same pgdir.
// However, try not to distinguish this case in your code, as this
// frequently leads to subtle bugs; there's an elegant way to handle
// everything in one code path.
//
// RETURNS:
// 0 on success
// -E_NO_MEM, if page table couldn't be allocated
//
// Hint: The TA solution is implemented using pgdir_walk, page_remove, and page2pa.
先看注释,page_insert()的作用是将给定的虚拟地址va对应的页面映射到给定的物理页面pp,页表项权限设置为perm|PTE_P。
存在以下几点要求:
- 如果已经存在一个页面和
va映射,应该先调用page_remove()删除该页面,并且使得TLB无效 - 如果有需要,可以分配一个页表并插入
pgdir中 - 插入成功时,
pp->ref自增。 - 插入成功,返回0,否则返回
-E_NO_MEM
注释中提醒需要注意:对同一个pp和同一个va进行两次重复的insert的情况,如果先使用page_remove()再pp->ref++,因为page_remove在ref为0时会调用page_free,可能会导致先free物理页,之后就再增加页面的引用数会产生问题,所以需要先pp->ref++,再page_remove()。
实现的思路是:先通过pgdir_walk()函数来获得pte,如果没有就进行创建。回顾pgdir_walk()函数,只会在create==false和page_alloc失败的情况下返回NULL,这里由于create==true(调用函数时设为1),所以只有可能是因为空间不足无法创建,因此返回-E_NO_MEM。得到pte后,对于对应的物理页面根据上述要求进行处理,添加引用数,如果存在映射关系则先删除,无效TLB,之后再进行映射。
代码如下:
int page_insert(pde_t *pgdir, struct PageInfo *pp, void *va, int perm)
{
// Fill this function in
pte_t *pte = pgdir_walk(pgdir, va, 1);
if (pte == NULL)
return -E_NO_MEM;
pp->pp_ref++;
if (*pte)
page_remove(pgdir, va); // page_remove中包含无效TLB
*pte = page2pa(pp) | perm | PTE_P;
return 0;
}
运行截图:
回答问题1
请你写出你实现的
pgdir_walk中的变量有哪些是虚拟地址,哪些是物理地址,以及为什么是这样。
A:
// A linear address 'la' has a three-part structure as follows:
//
// +--------10------+-------10-------+---------12----------+
// | Page Directory | Page Table | Offset within Page |
// | Index | Index | |
// +----------------+----------------+---------------------+
// \--- PDX(la) --/ \--- PTX(la) --/ \---- PGOFF(la) ----/
// \---------- PGNUM(la) ----------/
pgdir_walk中涉及到地址的变量有这些:
pte_t * pgdir_walk(pde_t *pgdir, const void *va, int create)
pgdir:虚拟地址。是pgdir_walk()的参数,是指向page directory的指针,表示是当前使用的页目录的基地址。
pte_t *dir_entry = &pgdir[dir_idx];
dir_entry:虚拟地址。先通过PDX(va)取出va的最高10位,作为页表目录的索引,dir_entry是该页表条目的地址。
pte_t *ptab = (pte_t *)KADDR(PTE_ADDR(pgdir[dir_idx]));
ptab:虚拟地址。首先通过PTE_ADDR把刚才得到的条目dir_entry转化为物理地址,即传入的虚拟地址va所在的 page table 的物理地址,再通过KADDR把该物理地址转为虚拟地址ptab,为对应page table的基地址。
return &ptab[tab_idx];
返回值&ptab[tab_idx]:虚拟地址,根据PTX(va)取出va的page table index,返回在page table对应条目的地址。
最后可以把这几个变量分别打印出来进行验证:
cprintf("pgdir_walk:pgdir=0x%08x\n", pgdir);
cprintf("pgdir_walk:dir_entry=0x%08x\n", dir_entry);
cprintf("pgdir_walk:ptab=0x%08x\n", ptab);
cprintf("pgdir_walk:&ptab[tab_idx]=0x%08x\n", &ptab[tab_idx]);
结果如图所示:
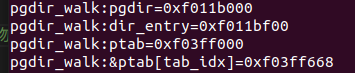
可以发现都是0xf开头的高地址,说明的确都是虚拟地址。
回答问题2
page_insert注释中提到了一个和reinsert相关的corner case,请问是否有办法在不特殊处理的情况下巧妙规避掉这个corner case。
A:我感觉本来也没有什么特殊处理。
因为对同一个pp和同一个va进行两次重复的insert的情况,只需要注意先先pp->ref++,再page_remove()就可以规避掉这个corner case。
因为如果先使用page_remove()再pp->ref++,因为page_remove在ref为0时会调用page_free,可能会导致先free物理页,尤其是当ref引用数刚好减为0时,该页面会被加入空闲链表。之后再加引用数,就使得空闲链表中存在着不空闲的页面,可能会被二次分配,产生问题。
回答问题3
阅读参考资料3,阐述使用
uvpt[PGNUM(va)]可以直接得到va对应的pte的原理。
A:
参考文档中介绍了UVPT这种机制:
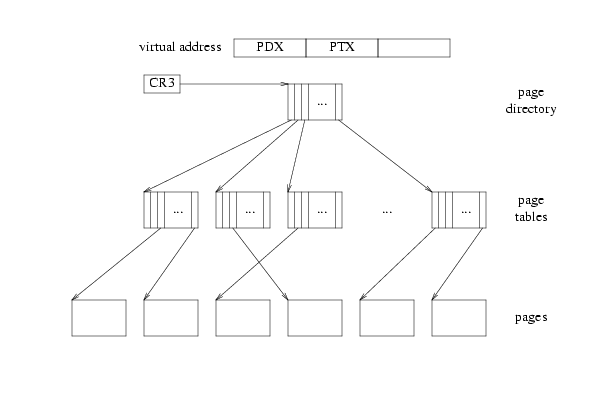
在把虚拟地址转换为物理地址的过程中,CR3指向页目录,地址的PDX部分在页目录中建立索引,从而生成页表,PTX部分在页表中建立索引以得到一个页,然后添加低位offset。但是,由于处理器对页目录、页表和页没有任何概念,所以内存中的某一页可以同时充当两到三个这样的页面。
处理器只跟随指针:
pd = lcr3();
pt = * (pd + 4 * PDX);
页面= * (pt + 4 * PTX);
如上图所示,从CR3开始,沿着三个箭头,然后停止。
如果在页目录中放入一个指针,该指针指向索引V处的自身,尝试转换一个PDX = V且PTX = V的虚拟地址,会沿着三个箭头到达页目录。因此,虚拟页面转换为包含页目录的页面。在JOS中,V是0x3BD,所以UVPD的虚拟地址是(0x3BD<<22)|(0x3BD<<12)。
现在,如果尝试转换一个PDX = V且PTX != V的虚拟地址,沿着CR3开始的三个箭头,结束时会到达页表(比通常高出一层,而不是像上一种情况中高出两层)。因此,具有PDX=V的虚拟页面集形成一个4MB的区域,对于处理器而言,该区域的页面内容就是页表本身。在JOS中,V是0x3BD,所以UVPT的虚拟地址是(0x3BD<<22)。
因此,由于巧妙地在页目录中插入了"no-op"箭头,已经将用作页目录和页表(通常实际上是不可见的)的页映射到虚拟地址空间中。
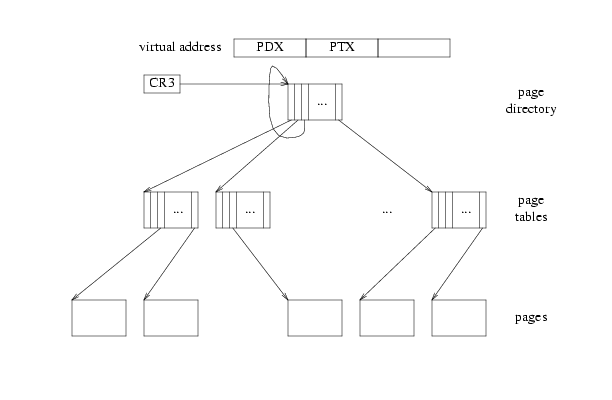
通常寻址:
cr3 PDX PTX PGOFF
------->页表目录---------二级页表-------->物理页面-------->值
uvpt[n]:
cr3 PDX PTX PGOFF
------->页表目录---------页表目录-------->二级页表-------->二级页表项
uvpd[n]:
cr3 PDX PTX PGOFF
------->页表目录---------页表目录-------->页表目录-------->目录表项
然后在mmu.h中找到宏PGNUM,通过PGNUM(la)可以获取虚拟地址la是第几个虚拟页面:
// A linear address 'la' has a three-part structure as follows:
//
// +--------10------+-------10-------+---------12----------+
// | Page Directory | Page Table | Offset within Page |
// | Index | Index | |
// +----------------+----------------+---------------------+
// \--- PDX(la) --/ \--- PTX(la) --/ \---- PGOFF(la) ----/
// \---------- PGNUM(la) ----------/
//
// The PDX, PTX, PGOFF, and PGNUM macros decompose linear addresses as shown.
// To construct a linear address la from PDX(la), PTX(la), and PGOFF(la),
// use PGADDR(PDX(la), PTX(la), PGOFF(la)).
// page number field of address
#define PGNUM(la) (((uintptr_t) (la)) >> PTXSHIFT)
UVPT处的内存布局如下图所示,UVPT共占了PTSIZE(4096*1024)大小的物理内存,由于每一个页表项4Bytes,一共有1024×1024个页表项,已经足够索引到所有页表项,并且该段地址以只读权限开放给用户态的程序。
* ULIM, MMIOBASE --> +------------------------------+ 0xef800000
* | Cur. Page Table (User R-) | R-/R- PTSIZE
* UVPT ----> +------------------------------+ 0xef400000
再在memlayout.h中找到uvpt[],uvpt[] 是个长为 $2^{20}$ 的 4Bytes 数组,和上面参考文档中介绍的一样,数组中的第$i$号 ( $0 ≤ i < 2^{20}$ ) 存的是第$i$页的PTE。
当访问uvpt[0]时:
- 取出虚拟地址的
PDX,查找页表目录的第pdx项,其值为pgdir[PDX(UVPT)],指向当前页表目录所在的页面,因此找到的二级目录是页表目录 - 取出
PTX,查找页表目录的第ptx项(第0项),得到第0个二级目录所在的页面 - 取出
OFFSET,查找页面的第OFFSET项(第0项),得到第0个二级目录的第0项,其值是一个页表项,对应第0个页面
所以当访问uvpt[n]时,其虚拟地址拆分为pdx, ptx, offset, 则能得到虚拟页面编号$n=ptx*1024+offset=(ptx«12)+offset$,因此访问uvpt[n]的值能得到第n个虚拟页面的页表项。
#if JOS_USER
// 与虚拟地址范围[UVPT, UVPT + PTSIZE]相对应的页面目录条目指向页面目录本身,因此页目录被视为页表和页目录
// The page directory entry corresponding to the virtual address range
// [UVPT, UVPT + PTSIZE) points to the page directory itself. Thus, the page
// directory is treated as a page table as well as a page directory.
//
// 将页目录作为页表处理的结果是:
// ①所有pte都可以通过虚拟地址为UVPT的“虚拟页表”访问,第N页的PTE存储在uvpt[N]中。
// One result of treating the page directory as a page table is that all PTEs
// can be accessed through a "virtual page table" at virtual address UVPT (to
// which uvpt is set in lib/entry.S). The PTE for page number N is stored in
// uvpt[N]. (It's worth drawing a diagram of this!)
//
// ②当前页目录的内容将总是在虚拟地址(UVPT + (UVPT >> PGSHIFT))中
// A second consequence is that the contents of the current page directory
// will always be available at virtual address (UVPT + (UVPT >> PGSHIFT)), to
// which uvpd is set in lib/entry.S.
//
extern volatile pte_t uvpt[]; // VA of "virtual page table"
extern volatile pde_t uvpd[]; // VA of current page directory
#endif
除了参考了老师发的资料,还参考了这篇博客:https://blog.csdn.net/weixin_43344725/article/details/89382013
任务三:
阅读MIT JOS LAB2 Part 3 部分关于内核地址空间的介绍,实现 Exercise 5 要求的相关代码,要求make grade通过并回答以下问题:
- 回答MIT JOS LAB2 Part 3 的 Question 5
- 回答MIT JOS LAB2 Part 3 的 Question 6。
Exercise 5
Fill in the missing code in
mem_init()after the call tocheck_page().Your code should now pass the
check_kern_pgdir()andcheck_page_installed_pgdir()checks.
mem_init()
阅读注释,理解需要补齐的三部分内容:
//////////////////////////////////////////////////////////////////////
// Now we set up virtual memory
//将pages数组映射到UPAGE地址区域以上
//[UPAGES, UPAGES+PTSIZE)映射到页表存储的物理地址 [pages, pages+4M),权限:PTE_U | PTE_P
//////////////////////////////////////////////////////////////////////
// Map 'pages' read-only by the user at linear address UPAGES
// Permissions:
// - the new image at UPAGES -- kernel R, user R
// (ie. perm = PTE_U | PTE_P)
// - pages itself -- kernel RW, user NONE
// 内核栈的映射
// 这里被划分成了[KSTACKTOP-KSTKSIZE, KSTACKTOP)和[KSTACKTOP-PTSIZE, KSTACKTOP-KSTKSIZE)两个部分
// 前一段需要映射到物理地址,后一段不需要
// 通过PADDR将bootstack转换为物理地址,然后以KSTACKTOP-KSTKSIZE为起点,KSTKSIZE为大小映射
// [KSTACKTOP-KSTKSIZE, KSTACKTOP)映射到[bootstack,bootstack+32KB)处,权限:PTE_W | PTE_P
//////////////////////////////////////////////////////////////////////
// Use the physical memory that 'bootstack' refers to as the kernel stack.
// The kernel stack grows down from virtual address KSTACKTOP.
// We consider the entire range from [KSTACKTOP-PTSIZE, KSTACKTOP)
// to be the kernel stack, but break this into two pieces:
// * [KSTACKTOP-KSTKSIZE, KSTACKTOP) -- backed by physical memory
// * [KSTACKTOP-PTSIZE, KSTACKTOP-KSTKSIZE) -- not backed; so if
// the kernel overflows its stack, it will fault rather than
// overwrite memory. Known as a "guard page".
// Permissions: kernel RW, user NONE
//映射整个内核的虚拟空间[KERNBASE, 2*32-KERNBASE)到物理地址 [0,256M),权限:PTE_W | PTE_P
//////////////////////////////////////////////////////////////////////
// Map all of physical memory at KERNBASE.
// Ie. the VA range [KERNBASE, 2^32) should map to
// the PA range [0, 2^32 - KERNBASE)
// We might not have 2^32 - KERNBASE bytes of physical memory, but
// we just set up the mapping anyway.
// Permissions: kernel RW, user NONE
代码实现:
// Your code goes here:
boot_map_region(kern_pgdir, UPAGES, npages * sizeof(struct PageInfo), PADDR(pages), PTE_U | PTE_P);
// Your code goes here:
boot_map_region(kern_pgdir, (KSTACKTOP - KSTKSIZE), KSTKSIZE, PADDR(bootstack), PTE_W | PTE_P);
// 0xffffffff - KERNBASE为KERNSIZE
// Your code goes here:
boot_map_region(kern_pgdir, KERNBASE, 0xffffffff - KERNBASE, 0, PTE_W | PTE_P);
运行截图:
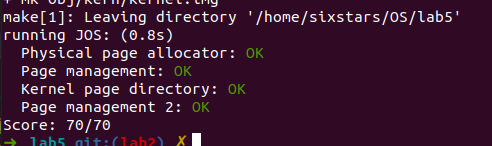
make qemu
make grade
Question 5
How much space overhead is there for managing memory, if we actually had the maximum amount of physical memory? How is this overhead broken down?
A:
首先要算出物理内存的最大值:
由于在mem_init()配置页表的过程中使用boot_map_regions()将pages映射到了UPAGES以上的区域:
//将pages数组映射到UPAGE地址区域以上
//[UPAGES, UPAGES+PTSIZE)映射到页表存储的物理地址 [pages, pages+4M),权限:PTE_U | PTE_P
boot_map_region(kern_pgdir, UPAGES, npages * sizeof(struct PageInfo), PADDR(pages), PTE_U | PTE_P);
* UVPT ----> +------------------------------+ 0xef400000
* | RO PAGES | R-/R- PTSIZE
* UPAGES ----> +------------------------------+ 0xef000000
如图所示,RO PAGES的空间是4MB(即所有页面所需的空间大小),pages的每个元素是struct PageInfo类型的结构体,大小为8Bytes(指针4B+short类型2B+对齐2B),所以一共有$4MB\div 8B=0.5M=512K$个结构体,即一共有512K个物理页。
struct PageInfo {
struct PageInfo *pp_link;
uint16_t pp_ref;
};
// 可以把PageInfo的大小打印出来
struct PageInfo test;
cprintf("struct PageInfo:%d\n", sizeof(test));
打印结果:
因为每个物理页大小为4KB(因为偏移是12位,所以页面大小是4KB),所以总的物理内存为$512K\times 4KB=2GB$。
再根据虚拟地址的结构:
// A linear address 'la' has a three-part structure as follows:
//
// +--------10------+-------10-------+---------12----------+
// | Page Directory | Page Table | Offset within Page |
// | Index | Index | |
// +----------------+----------------+---------------------+
寻址的顺序是Page Directory->Page Table->Page,因为物理内存是2GB,所以一共有512K张物理页面。因为一个Page Table可以寻址$2^{10}$个页面,所以一共需要$512K\div 2^{10}=512$个Page Table。由于每个页表项(pte_t)大小为4B(32位),页表所需的空间是:$4B \times 2^{10} \times 512 = 2MB$。
typedef uint32_t pte_t;
typedef uint32_t pde_t;
因为一个Page Directory可以寻址$2^{10}$个页表,所以只需一个页目录就可以满足512张页表的寻址。同样每个页目录项(pde_t)大小为4B,页目录所需的空间是:$4B \times 2^{10} = 4KB$。
所以管理内存一共的空间开销为:$页目录空间+页表空间+页空间=4KB+2MB+4MB=6MB+4KB$。
如果想要把开销减小,可以设置大一点的PGSIZE。
Question 6
Revisit the page table setup in
kern/entry.Sandkern/entrypgdir.c. Immediately after we turn on paging, EIP is still a low number (a little over 1MB). At what point do we transition to running at an EIP aboveKERNBASE? What makes it possible for us to continue executing at a low EIP between when we enable paging and when we begin running at an EIP aboveKERNBASE? Why is this transition necessary?
A:
查看了kern/entry.S中的代码,首先通过kern/entrypgdir.c建立了一个临时的页目录,映射的空间大小为4MB,一直到分页机制建立好时,CPU都使用了low EIP。
entry:
movw $0x1234,0x472 # warm boot
# We haven't set up virtual memory yet, so we're running from
# the physical address the boot loader loaded the kernel at: 1MB
# (plus a few bytes). However, the C code is linked to run at
# KERNBASE+1MB. Hence, we set up a trivial page directory that
# translates virtual addresses [KERNBASE, KERNBASE+4MB) to
# physical addresses [0, 4MB). This 4MB region will be
# sufficient until we set up our real page table in mem_init
# in lab 2.
# Load the physical address of entry_pgdir into cr3. entry_pgdir
# is defined in entrypgdir.c.
movl $(RELOC(entry_pgdir)), %eax
movl %eax, %cr3
# Turn on paging.
movl %cr0, %eax
orl $(CR0_PE|CR0_PG|CR0_WP), %eax
movl %eax, %cr0
# Now paging is enabled, but we're still running at a low EIP
# (why is this okay?). Jump up above KERNBASE before entering
# C code.
mov $relocated, %eax
jmp *%eax
可以看到最后一段注释:当执行完指令movl %eax, %cr0后,启用分页,控制流通过mov $relocated, %eax jmp *%eax,跳转到了KERNBASE以上的高地址部分。
并且由于虚拟地址中[0,4MB]的低地址和KERNBASE以上的高地址区域[KERNBASE,KERNBASE + 4MB]都被映射在同一片物理内存[0,4MB]中,所以无论EIP在高位还是在低位都可以运行。这样做是必需的,因为如果只映射高地址,在开启分页模式后,仍然需要访问低地址,这时就会出错。
// kern/entrypgdir.c中的映射
__attribute__((__aligned__(PGSIZE)))
pde_t entry_pgdir[NPDENTRIES] = {
// Map VA's [0, 4MB) to PA's [0, 4MB)
[0]
= ((uintptr_t)entry_pgtable - KERNBASE) + PTE_P,
// Map VA's [KERNBASE, KERNBASE+4MB) to PA's [0, 4MB)
[KERNBASE>>PDXSHIFT]
= ((uintptr_t)entry_pgtable - KERNBASE) + PTE_P + PTE_W
};
任务四:
根据参考资料和xv6的源码,请简要描述xv6系统和JOS系统在内存管理机制上的异同点,字数不限。
A:(这里xv6源码看的是第一次实验课上装的xv6)
xv6内存管理机制:
1、entry.S
首先在entry.S中看到开启了4MB内存页,并设置了页目录开启页表,页表的基地址在entrypgdir中(变量在main.c中声明),通过调整cr0寄存器的位开启页表。
# Entering xv6 on boot processor, with paging off.
.globl entry
entry:
# Turn on page size extension for 4Mbyte pages
movl %cr4, %eax
orl $(CR4_PSE), %eax
movl %eax, %cr4
# Set page directory
movl $(V2P_WO(entrypgdir)), %eax
movl %eax, %cr3
# Turn on paging.
movl %cr0, %eax
orl $(CR0_PG|CR0_WP), %eax
movl %eax, %cr0
# Set up the stack pointer.
movl $(stack + KSTACKSIZE), %esp
# Jump to main(), and switch to executing at
# high addresses. The indirect call is needed because
# the assembler produces a PC-relative instruction
# for a direct jump.
mov $main, %eax
jmp *%eax
// The boot page table used in entry.S and entryother.S.
// Page directories (and page tables) must start on page boundaries,
// hence the __aligned__ attribute.
// PTE_PS in a page directory entry enables 4Mbyte pages.
__attribute__((__aligned__(PGSIZE)))
pde_t entrypgdir[NPDENTRIES] = {
// Map VA's [0, 4MB) to PA's [0, 4MB)
[0] = (0) | PTE_P | PTE_W | PTE_PS,
// Map VA's [KERNBASE, KERNBASE+4MB) to PA's [0, 4MB)
[KERNBASE>>PDXSHIFT] = (0) | PTE_P | PTE_W | PTE_PS,
};
上述的的代码把虚拟地址空间中的[0, 4MB) 和[KERNBASE, KERNBASE+4MB)都映射到了物理地址中的 [0, 4MB),和JOS中的映射逻辑是一样。
2、建立一个地址空间
之后通过jmp跳转到c语言到main.c:
// Bootstrap processor starts running C code here.
// Allocate a real stack and switch to it, first
// doing some setup required for memory allocator to work.
int main(void)
{
kinit1(end, P2V(4*1024*1024)); // phys page allocator
kvmalloc(); // kernel page table
mpinit(); // detect other processors
lapicinit(); // interrupt controller
seginit(); // segment descriptors
picinit(); // disable pic
ioapicinit(); // another interrupt controller
consoleinit(); // console hardware
uartinit(); // serial port
pinit(); // process table
tvinit(); // trap vectors
binit(); // buffer cache
fileinit(); // file table
ideinit(); // disk
startothers(); // start other processors
kinit2(P2V(4*1024*1024), P2V(PHYSTOP)); // must come after startothers()
userinit(); // first user process
mpmain(); // finish this processor's setup
}
在main()中调用kvmalloc()初始化内核新页表:
// Allocate one page table for the machine for the kernel address
// space for scheduler processes.
void kvmalloc(void)
{
kpgdir = setupkvm();
switchkvm();
}
其中调用了函数setupkvm,首先会分配一页内存来放置页目录,然后调用 mappages 来建立内核需要的映射,这些映射可以在 kmap中找到。这里的映射包括内核的指令和数据,PHYSTOP 以下的物理内存,以及 I/O 设备所占的内存。setupkvm 不会建立任何用户内存的映射,这些映射稍后会建立。
#define PHYSTOP 0xE000000 // Top physical memory
// Set up kernel part of a page table.
pde_t* setupkvm(void)
{
pde_t *pgdir;
struct kmap *k;
if((pgdir = (pde_t*)kalloc()) == 0)
return 0;
memset(pgdir, 0, PGSIZE);
if (P2V(PHYSTOP) > (void*)DEVSPACE)
panic("PHYSTOP too high");
for(k = kmap; k < &kmap[NELEM(kmap)]; k++)
if(mappages(pgdir, k->virt, k->phys_end - k->phys_start, //调用mappages
(uint)k->phys_start, k->perm) < 0) {
freevm(pgdir);
return 0;
}
return pgdir;
}
mappages的作用是在页表中,以页的级别建立一段虚拟内存到一段物理内存的映射。对于每一个待映射虚拟地址,mappages 调用 walkpgdir 来找到该地址对应的 PTE 地址。然后初始化该 PTE 以保存对应物理页号、许可级别(PTE_W 和/或 PTE_U)以及 PTE_P 位来标记该 PTE 是否是有效的。
// Create PTEs for virtual addresses starting at va that refer to physical addresses starting at pa. va and size might not be page-aligned.
// 这里mappages的作用是:为映射到pa的虚拟地址va创建PTE
// 类似于JOS中的boot_map_region:把虚拟地址[va, va+size)映射到物理地址[pa, pa+size],并且把映射关系加入到页表pgdir,修改使用权限位。
static int mappages(pde_t *pgdir, void *va, uint size, uint pa, int perm)
{
char *a, *last;
pte_t *pte;
a = (char*)PGROUNDDOWN((uint)va);
last = (char*)PGROUNDDOWN(((uint)va) + size - 1);
for(;;){
//对于每一个待映射的虚拟地址,调用walkpgdir找到该地址对应的PTE地址,然后保存对应的物理地址、权限。
if((pte = walkpgdir(pgdir, a, 1)) == 0)
return -1;
if(*pte & PTE_P)
panic("remap");
*pte = pa | perm | PTE_P;
if(a == last)
break;
a += PGSIZE;
pa += PGSIZE;
}
return 0;
}
walkpgdir的目的是为一个虚拟地址寻找 PTE 的过程,根据va的前十位来先找到在页目录的条目。如果该条目不存在,说明该页表不存在;如果alloc参数被设置,walkpgdir会分配页表页并将其物理地址放到页目录中。最后用虚拟地址的接下来10位来找到其在页表中的PTE地址。
// 相当于JOS中的pgdir_walk()
// Return the address of the PTE in page table pgdir that corresponds to virtual address va.
// If alloc!=0,create any required page table pages.
static pte_t * walkpgdir(pde_t *pgdir, const void *va, int alloc)
{
pde_t *pde;
pte_t *pgtab;
pde = &pgdir[PDX(va)];
if (*pde & PTE_P)
{
pgtab = (pte_t *)P2V(PTE_ADDR(*pde));
}
else
{
if (!alloc || (pgtab = (pte_t *)kalloc()) == 0)
return 0;
// Make sure all those PTE_P bits are zero.
memset(pgtab, 0, PGSIZE);
// The permissions here are overly generous, but they can
// be further restricted by the permissions in the page table
// entries, if necessary.
*pde = V2P(pgtab) | PTE_P | PTE_W | PTE_U;
}
return &pgtab[PTX(va)];
}
在setupkvm中,所有的映射最后都存储在kmap结构体中:
// This table defines the kernel's mappings, which are present in every process's page table.
static struct kmap {
void *virt;
uint phys_start;
uint phys_end;
int perm;
} kmap[] = {
{ (void*)KERNBASE, 0, EXTMEM, PTE_W}, // I/O space
{ (void*)KERNLINK, V2P(KERNLINK), V2P(data), 0}, // kern text+rodata
{ (void*)data, V2P(data), PHYSTOP, PTE_W}, // kern data+memory
{ (void*)DEVSPACE, DEVSPACE, 0, PTE_W}, // more devices
};
xv6中虚拟内存和物理内存的映射如下图:
3、物理内存的分配
在运行时,内核需要为页表、进程的用户内存、内核栈及管道缓冲区分配空闲的物理内存。
xv6 使用从内核结尾到 PHYSTOP 之间的物理内存为运行时分配提供内存资源。每次分配调用kalloc,会将整块 4096 字节大小的页分配出去。xv6 还会通过维护一个物理页组成的链表(结构体 struct run)来寻找空闲页。分配器将每个空闲页的 run 结构体保存在该空闲页本身中(因为空闲页中没有其他数据)。分配器还用一个spin lock来保护空闲链表。链表和这个锁都封装在一个结构体kmem中。当分配内存时需要将页移出该链表,而释放内存需要将页加入该链表。
struct run {
struct run *next;
};
struct {
struct spinlock lock;
int use_lock;
struct run *freelist;
} kmem;
为了让分配器能够初始化该空闲链表,所有的物理内存都必须要建立起映射,但是建立包含这些映射的页表又必须要分配存放页表的页。xv6 通过在 entry 中使用一个特别的页分配器来解决这个问题。该分配器会在内核数据部分的后面分配内存。该分配器不支持释放内存,并受限于 entrypgdir 中规定的 4MB 分配大小。即便如此,该分配器还是足够为内核的第一个页表分配出内存。
main 函数调用了 kinit1 和 kinit2 两个函数对分配器进行初始化。这样做是由于 main 中的大部分代码都不能使用锁以及 4MB 以上的内存。kinit1 在前 4MB 进行了不需要锁的内存分配。
在main()中第一个调用的函数是kinit1(end, P2V(4*1024*1024));,进行第一阶段的初始化物理内存,初始化内核末尾到物理内存4MB的物理内存空间为未使用,再调用freerange将空闲内存加入到空闲内存链表中。
// main() calls kinit1() while still using entrypgdir to place just
// the pages mapped by entrypgdir on free list.
// 这里的vstart就是end的地址,在JOS里也遇到过,是.bss段结束的地方
// vend是KERNBASE + 128MB = 0x86400000
// 这里就是把[vstart, 0x86400000]的内存按页(4kb大小)进行free,kree这里会把他插入到freelist中
void kinit1(void *vstart, void *vend)
{
initlock(&kmem.lock, "kmem");
kmem.use_lock = 0;
freerange(vstart, vend); //调用了freerange()
}
在内核构建了新页表后,能够完全访问内核的虚拟地址空间,就到了初始化物理内存的第二阶段,调用了函数kinit2(P2V(4*1024*1024), P2V(PHYSTOP));,目的是初始化剩余内核空间到PHYSTOP为未使用,开始了锁机制保护空闲内存链表。(kinit2 允许锁的使用,并使得更多的内存可用于分配。)
// main() calls kinit2() with the rest of the physical pages
// after installing a full page table that maps them on all cores.
void kinit2(void *vstart, void *vend)
{
freerange(vstart, vend);
kmem.use_lock = 1;
}
kinit1 和 kinit2 都调用了freerange 将内存加入空闲链表中,该函数是通过对每一页调用 kfree 实现该功能。一个 PTE 只能指向一个 4096 字节对齐的物理地址(即是 4096 的倍数),因此 freerange 用 PGROUNDUP 来保证分配器只会释放对齐的物理地址。分配器原本一开始没有内存可用,正是对 kfree 的调用将可用内存交给了分配器来管理。
void freerange(void *vstart, void *vend)
{
char *p;
p = (char*)PGROUNDUP((uint)vstart);
for(; p + PGSIZE <= (char*)vend; p += PGSIZE)
kfree(p); //调用kfree()
}
分配器用映射到高内存区域的虚拟地址找到对应的物理页,而非物理地址。所以 kinit 会使用 p2v(PHYSTOP)来将 PHYSTOP(一个物理地址)翻译为虚拟地址。分配器有时将地址看作是整型,这是为了对其进行运算(譬如在 kinit 中遍历所有页);而有时将地址看作读写内存用的指针(譬如操作每个页中的 run 结构体);对地址的双重使用导致分配器代码中充满了类型转换。另外一个原因是,释放和分配内存隐性地改变了内存的类型。
函数 kfree首先将被释放内存的每一字节设为 1。这使得访问已被释放内存的代码所读到的不是原有数据,而是垃圾数据;这样做能让这种错误的代码尽早崩溃。接下来 kfree 把 v 转换为一个指向结构体 struct run 的指针,在 r->next 中保存原有空闲链表的表头,然后将当前的空闲链表设置为 r。kalloc 移除并返回空闲链表的表头。
// Free the page of physical memory pointed at by v,
// which normally should have been returned by a
// call to kalloc(). (The exception is when
// initializing the allocator; see kinit above.)
void kfree(char *v)
{
struct run *r;
if((uint)v % PGSIZE || v < end || V2P(v) >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(v, 1, PGSIZE);
if(kmem.use_lock)
acquire(&kmem.lock);
r = (struct run*)v;
r->next = kmem.freelist;
kmem.freelist = r;
if(kmem.use_lock)
release(&kmem.lock);
}
// Allocate one 4096-byte page of physical memory.
// Returns a pointer that the kernel can use.
// Returns 0 if the memory cannot be allocated.
char* kalloc(void)
{
struct run *r;
if(kmem.use_lock)
acquire(&kmem.lock);
r = kmem.freelist;
if(r)
kmem.freelist = r->next;
if(kmem.use_lock)
release(&kmem.lock);
return (char*)r;
}
xv6对上层提供kalloc和kfree接口来管理物理内存,上层无需知道具体的细节,kalloc返回虚拟地址空间的地址,kfree以虚拟地址为参数,通过kalloc和kfree能够有效管理物理内存,让上层只需要考虑虚拟地址空间。
kalloc分配4KB(相当于一页)的物理内存,并返回一个内核可以使用的指针,如果返回0说明这页无法被分配;kfree以虚拟地址为参数,用来释放一页的内存空间。
相同点:
1、虚拟地址构成相同:一共都有32位,前10位为页目录索引,中间10位为页表索引,最后12位为偏移,都分成了二级页表(所以虚拟地址到物理地址的转换过程也是一样的)。
// xv6
// A virtual address 'la' has a three-part structure as follows:
//
// +--------10------+-------10-------+---------12----------+
// | Page Directory | Page Table | Offset within Page |
// | Index | Index | |
// +----------------+----------------+---------------------+
// \--- PDX(va) --/ \--- PTX(va) --/
// JOS
// A linear address 'la' has a three-part structure as follows:
//
// +--------10------+-------10-------+---------12----------+
// | Page Directory | Page Table | Offset within Page |
// | Index | Index | |
// +----------------+----------------+---------------------+
// \--- PDX(la) --/ \--- PTX(la) --/ \---- PGOFF(la) ----/
// \---------- PGNUM(la) ----------/
原因是:页面大小相同都是4KB,所以offset都是12位,因为是32位的机器,页表条目都是4B,所以$4KB/4B=1K=2^{10}$,所以page table共有10位,同理page directory也是10位,因为$4B*2^{10}/4B=2^{10}$。
所以在宏中设置的页表中的相关信息也都相同:每个页目录都有1024个条目,每一个页表中也有1024个条目,每一页的大小4096字节,也就是4KB。


2、物理内存最多都是2GB
3、xv6和JOS都在最开始完成了虚拟地址空间中的[0, 4MB) 和[KERNBASE, KERNBASE+4MB)都映射到了物理地址中的 [0, 4MB),并且都通过一条间接转移(地址存在寄存器中)指令使得EIP指向高址端,从而内核真正实现在高址端运行
不同点:
1、JOS中应用了UVPT的技术可以快速找到PTE,但是xv6没有
2、xv6中KERNBASE是0x80000000,JOS中是0xF0000000
3、在xv6中通过 struct run来寻找空闲页,并且为了保护空闲链表,分配器还用了spin lock,并把链表和锁都封装在一个结构体kmem中。当分配内存时需要将页移出该链表,而释放内存需要将页加入该链表。
struct run {
struct run *next;
};
struct {
struct spinlock lock;
int use_lock;
struct run *freelist;
} kmem;
在JOS中每个物理页面都通过PageInfo进行对应,通过pp_link指向下一个空闲页,通过pp_ref表示页面被引用数,所以JOS是支持共享页面的。所有的空闲页存储在static struct PageInfo *page_free_list; 中。
struct PageInfo {
// pp_link指向下一个空闲页
struct PageInfo *pp_link;
// pp_ref表示页面被引用数,如果为0,表示是空闲页
uint16_t pp_ref;
};
因为在xv6中,没有记录页面被引用数,并且通过锁保护,不允许同时访问一个页面,所以xv6不支持共享页面。
xv6中以页为粒度保护页面,但是JOS中不保护页面(之后的Lab中也没有)。
并且,由于xv6中没有PageInfo,所以不像JOS中有page_lookup()函数返回对应的PageInfo。
当JOS中要释放页面时,通过引用数是否为0,判断是否可以释放;但是在xv6中是通过锁的情况。
4、页表条目的标志不同。
在xv6中,为了减少页表的工作负担,设有4MB大小超级页,可以通过设置PTE_PS 进行标志:
// Page table/directory entry flags.
#define PTE_P 0x001 // Present
#define PTE_W 0x002 // Writeable
#define PTE_U 0x004 // User
#define PTE_PS 0x080 // Page Size
__attribute__((__aligned__(PGSIZE)))
pde_t entrypgdir[NPDENTRIES] = {
// Map VA's [0, 4MB) to PA's [0, 4MB)
[0] = (0) | PTE_P | PTE_W | PTE_PS,
// Map VA's [KERNBASE, KERNBASE+4MB) to PA's [0, 4MB)
[KERNBASE>>PDXSHIFT] = (0) | PTE_P | PTE_W | PTE_PS, //标记超级页
};
但是在JOS中没有超级页,但是有其他标志:
// Page table/directory entry flags.
#define PTE_P 0x001 // Present
#define PTE_W 0x002 // Writeable
#define PTE_U 0x004 // User
#define PTE_PWT 0x008 // Write-Through
#define PTE_PCD 0x010 // Cache-Disable
#define PTE_A 0x020 // Accessed
#define PTE_D 0x040 // Dirty
#define PTE_PS 0x080 // Page Size
#define PTE_G 0x100 // Global
__attribute__((__aligned__(PGSIZE)))
pde_t entry_pgdir[NPDENTRIES] = {
// Map VA's [0, 4MB) to PA's [0, 4MB)
[0]
= ((uintptr_t)entry_pgtable - KERNBASE) + PTE_P,
// Map VA's [KERNBASE, KERNBASE+4MB) to PA's [0, 4MB)
[KERNBASE>>PDXSHIFT]
= ((uintptr_t)entry_pgtable - KERNBASE) + PTE_P + PTE_W
};
5、在JOS中,内存管理的顺序是:
为页目录分配空间 kern_pgdir = (pde_t *) boot_alloc(PGSIZE);
--> 对于存储PageInfo的数组pages进行空间分配 pages = (struct PageInfo *)boot_alloc(npages * sizeof(struct PageInfo));
--> page_init始化页的数据结构以及初始化能够分配的空闲物理空间页的链表(page_free_list)
JOS中直到page_init时才把[EXTPHYSMEM, ...)中除了被kernel占用的地方之外标记为可用,加入page_free_list。但是在xv6中,一开始就调用了kinit1,把内核末尾到物理内存4MB的物理内存空间初始化为未使用,加入空闲链表。
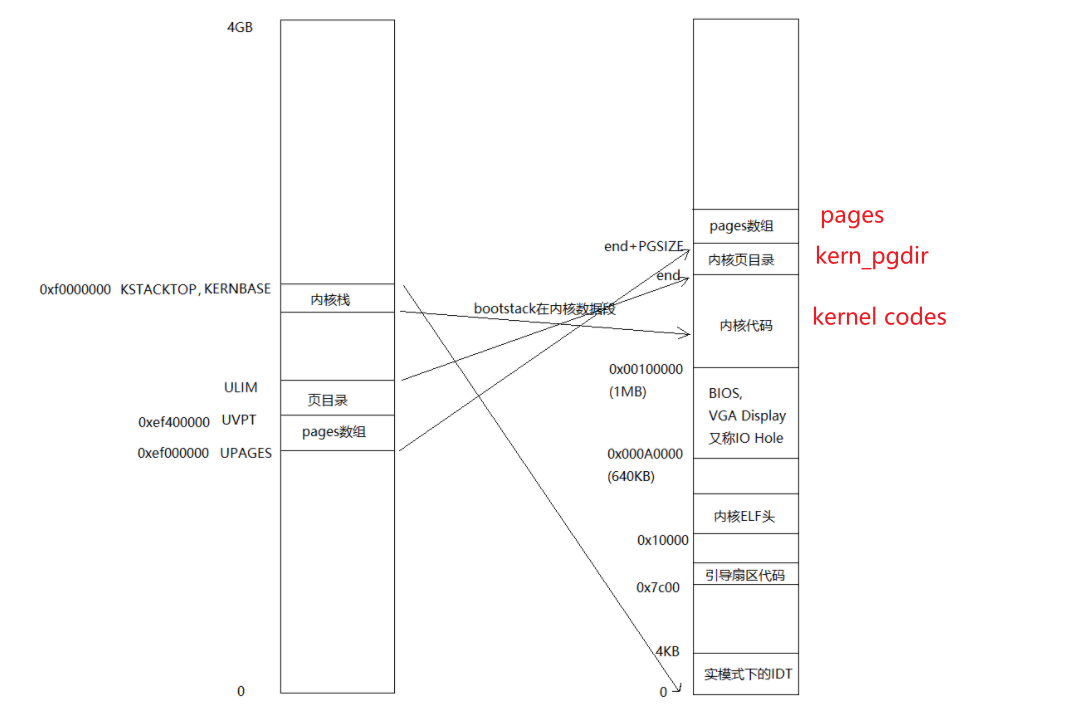
6、在JOS中在物理内存中分配空间分为page_alloc和boot_alloc,其中boot_alloc函数只在建立虚拟内存系统时使用,真正分配器是page_alloc。有这样的区分是因为一开始和PageInfo相关的数据结构,比如空闲链表都还没有建立起来。kern_pgdir和pages都是通过boot_alloc分配的,在物理内存中的位置如图所示:
但在xv6中boot_alloc和page_alloc整合成kalloc,xv6在setupkvm()的过程中直接通过kalloc分配一页内存来放置页目录,pgdir = (pde_t *)kalloc(),后续分配页面的操作也是通过kalloc。
7、JOS中有实现TLB,xv6中没有
8、在xv6中,有kmap`结构定义了内核的映射,并会出现在每个进程的页表中,但是JOS中没有。
// This table defines the kernel's mappings, which are present in every process's page table.
static struct kmap {
void *virt;
uint phys_start;
uint phys_end;
int perm;
} kmap[] = {
{ (void*)KERNBASE, 0, EXTMEM, PTE_W}, // I/O space
{ (void*)KERNLINK, V2P(KERNLINK), V2P(data), 0}, // kern text+rodata
{ (void*)data, V2P(data), PHYSTOP, PTE_W}, // kern data+memory
{ (void*)DEVSPACE, DEVSPACE, 0, PTE_W}, // more devices
};